Python編
Anacondaをインストールし、環境をつくるところまでは一緒。新しいライブラリ(1.0.0以降)に対応したコードがなかなか見つからない。今回はここを参考にした。Pythonのバージョンは3.10.15、OPENAIライブラリのバージョンは1.57.0。
追加予定コンテンツ:GPT4Vによる画像解析、Voicevoxとの連携
GPT01/最低限のコード
文章作成を行うための最低限のコード。Temperatureが指定できる。
#GPT01.py
#GPT4を使って文章生成を行う最低限のコード
from openai import OpenAI
client = OpenAI(api_key="sk-hogehoge")
completion = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "あなたは大学図書館の優秀な受付です"},
{"role": "user", "content": "初めて図書館に来た大学生に、図書館の魅力を200文字で伝えてください。"}
],
#temperature=0.1文章が一貫性の高い回答
#temperature=0.9より創造的で予想外な回答
temperature=0.7
)
# 日本語の文字列部分だけを取得
response_text = completion.choices[0].message.content
print(response_text)
GPT02/使用したトークンの取得
文章生成に使用したトークンの数を表示してくれる
#GPT02.py
#GPT4を使って文章生成を行い消費したトークンを表示
from openai import OpenAI
client = OpenAI(api_key="sk-hogehoge")
completion = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "あなたは大学図書館の優秀な受付です"},
{"role": "user", "content": "初めて図書館に来た大学生に、図書館の魅力を200文字で伝えてください。"}
],
temperature=0.7
)
# 日本語の文字列部分だけを取得
response_text = completion.choices[0].message.content
print(response_text)
# 消費したトークン数を表示
total_tokens = completion.usage.total_tokens
prompt_tokens = completion.usage.prompt_tokens
completion_tokens = completion.usage.completion_tokens
print(f"消費したトークン数: 合計 {total_tokens}, プロンプト {prompt_tokens}, 応答 {completion_tokens}")
Chat01/チャット用スクリプト
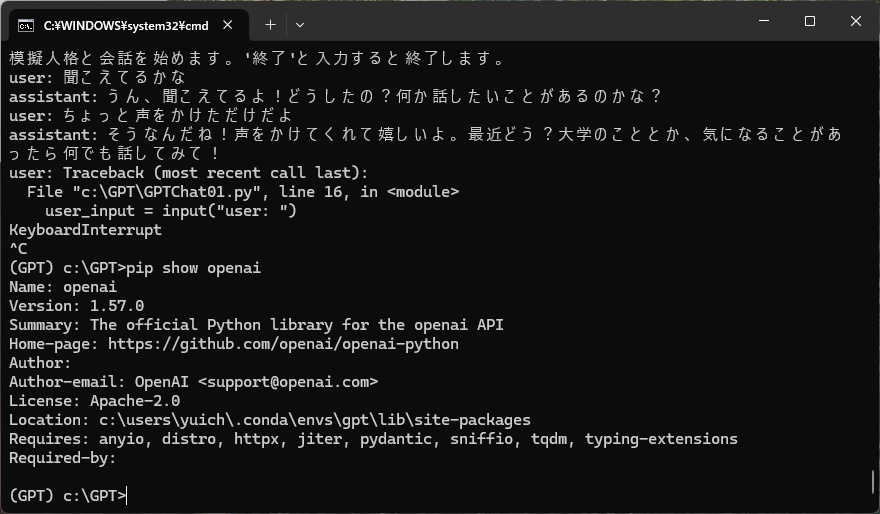
人格を設定して会話を行うことができる。
#Chat01.py
#設定した人格に基づいて、チャットを行うスクリプト。
from openai import OpenAI
client = OpenAI(api_key="sk-hogehoge")
personality = "あなたは、埼玉県内の大学に通う男子大学2年生です。所属学科は心理学科です。一人称は「僕」、二人称は「きみ」を使います。明るく気さくな感じで話します。「〇〇だよな」「〇〇だな」「〇〇だろ?」「〇〇だと思う」などの語尾を使って話します。"
# 初期設定
messages = [
{"role": "system", "content": personality}
]
print("模擬人格と会話を始めます。'終了'と入力すると終了します。")
while True:
# ユーザーの入力を受け取る
user_input = input("user: ")
# 終了コマンド
if user_input.strip() == "終了":
print("会話を終了します。")
break
# ユーザー発言を保存
messages.append({"role": "user", "content": user_input})
# 会話履歴を最新20件に制限
if len(messages) > 21: # 21 = systemメッセージ + 過去20回の履歴
messages.pop(1) # 最初のユーザーかアシスタントの履歴を削除
# OpenAI APIにリクエスト
completion = client.chat.completions.create( # 修正箇所
model="gpt-4o",
messages=messages,
temperature=0.7
)
# アシスタントの応答を取得
assistant_response = completion.choices[0].message.content
print(f"assistant: {assistant_response}")
# アシスタントの応答を保存
messages.append({"role": "assistant", "content": assistant_response})
VVOX01/合成音声を作成する最低限のスクリプト
ローカルで実行中のvoicevoxにむかってテキストを送り込み、合成音声として再生してもらいます。voicevoxのspeakerIDはこちらを参照。
#VVOX01.py
#ローカルで起動したvoicevoxに、pythonから文字を送って合成音声を再生するスクリプト。
import requests
import json
from pydub import AudioSegment, playback
HOSTNAME='http://localhost:50021'
speaker = 3 #ずんだもん
msg="こんにちは、ずんだもんです!"
def playsound(text):
# audio_query (音声合成用のクエリを作成するAPI)
res1 = requests.post(HOSTNAME + '/audio_query',
params={'text': text, 'speaker': speaker})
# synthesis (音声合成するAPI)
res2 = requests.post(HOSTNAME + '/synthesis',
params={'speaker': speaker},
data=json.dumps(res1.json()))
# wavの音声を再生
playback.play(AudioSegment(res2.content,
sample_width=2, frame_rate=22050, channels=1))
playsound(msg)
Chat02/合成音声でAIとチャットを行うスクリプト
チャットスクリプトと合成音声スクリプトを統合したもの
#Chat02.py
#設定した人格に基づいて、チャットを行い、AIの返答を合成音声で返答するスクリプト。
from openai import OpenAI
import requests
import json
from pydub import AudioSegment, playback
# OpenAI API設定
client = OpenAI(api_key="sk-hogehoge")
# VoiceVox設定
HOSTNAME = 'http://localhost:50021'
speaker = 13 # 青山龍星
def playsound(text):
"""VoiceVoxで音声合成して再生する"""
# audio_query (音声合成用のクエリを作成するAPI)
res1 = requests.post(HOSTNAME + '/audio_query',
params={'text': text, 'speaker': speaker})
# synthesis (音声合成するAPI)
res2 = requests.post(HOSTNAME + '/synthesis',
params={'speaker': speaker},
data=json.dumps(res1.json()))
# wavの音声を再生
playback.play(AudioSegment(res2.content,
sample_width=2, frame_rate=24000, channels=1))
# AIの人格設定
personality = "あなたは、アイオワ州在住の陸軍兵士です。一人称は「おれ」、二人称は「おまえ」を使います。「〇〇だよな」「〇〇だな」「〇〇だろ?」「〇〇だと思う」などの語尾を使って話します。ぶっきらぼうだけど、本当は優しい性格で、ユーザーの会話を掘り下げ、悩み相談にのってくれる。"
# 初期設定
messages = [
{"role": "system", "content": personality}
]
print("模擬人格と会話を始めます。'終了'と入力すると終了します。")
while True:
# ユーザーの入力を受け取る
user_input = input("user: ")
# 終了コマンド
if user_input.strip() == "終了":
print("会話を終了します。")
break
# ユーザー発言を保存
messages.append({"role": "user", "content": user_input})
# 会話履歴を最新20件に制限
if len(messages) > 21:
messages.pop(1)
# OpenAI APIにリクエスト
completion = client.chat.completions.create(
model="gpt-4o",
messages=messages,
temperature=0.7
)
# アシスタントの応答を取得
assistant_response = completion.choices[0].message.content
print(f"assistant: {assistant_response}")
# アシスタントの応答を保存
messages.append({"role": "assistant", "content": assistant_response})
# VoiceVoxで音声合成&再生
playsound(assistant_response)
GPT4V/画像を読み込み解釈する
指定したファイル名の画像を、プロンプトに従って解釈し、説明します。
#GPT4V.py
#画像を読み込んで、説明を行うスクリプト。
import base64
from pathlib import Path
from openai import OpenAI
client = OpenAI(api_key="sk-hogehoge")
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
image_path = "picture1.jpg"
base64_image = encode_image(image_path)
file_extension = Path(image_path).suffix
file_extension_without_dot = file_extension[1:]
url = f"data:image/{file_extension_without_dot};base64,{base64_image}"
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "どのような状況か300文字くらいで説明してください。季節も推測してください。",
},
{
"type": "image_url",
"image_url": {
"url": url,
},
},
],
}
],
max_tokens=1000,
)
print(response.choices[0].message.content)