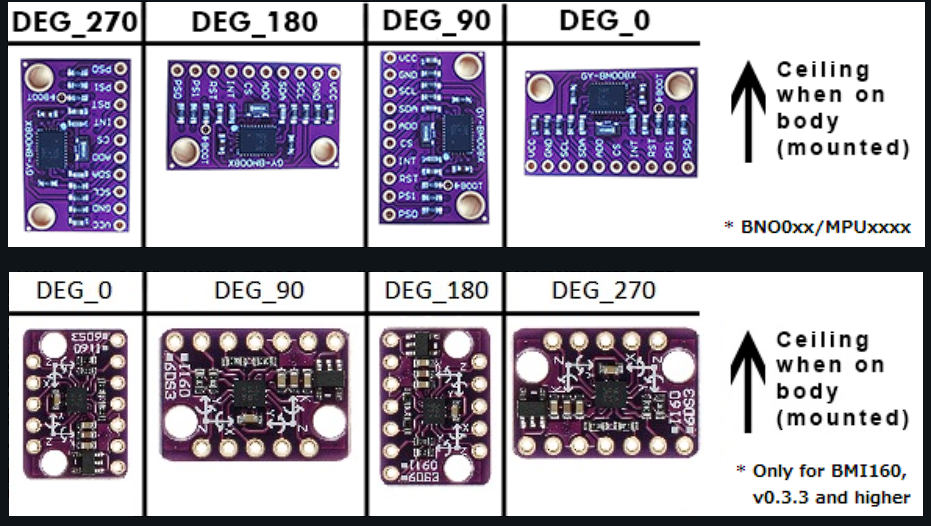
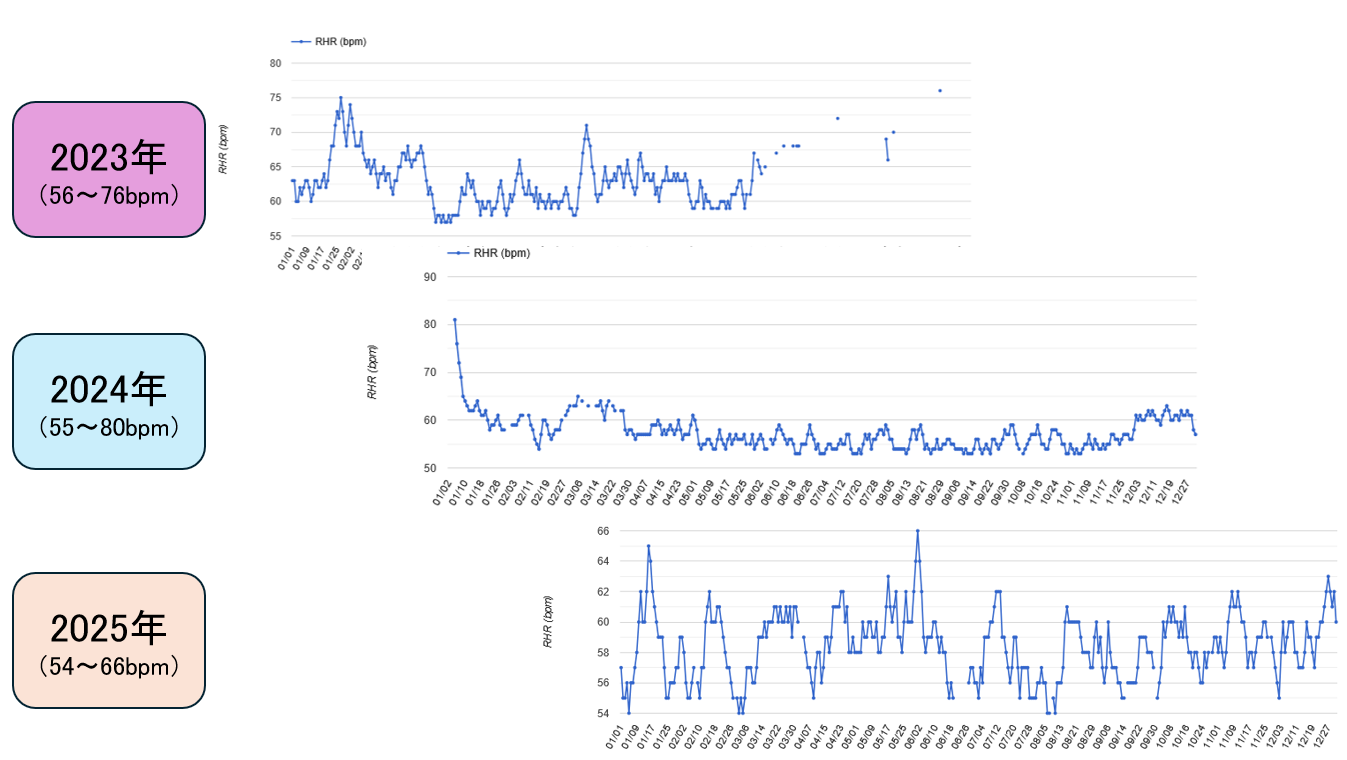
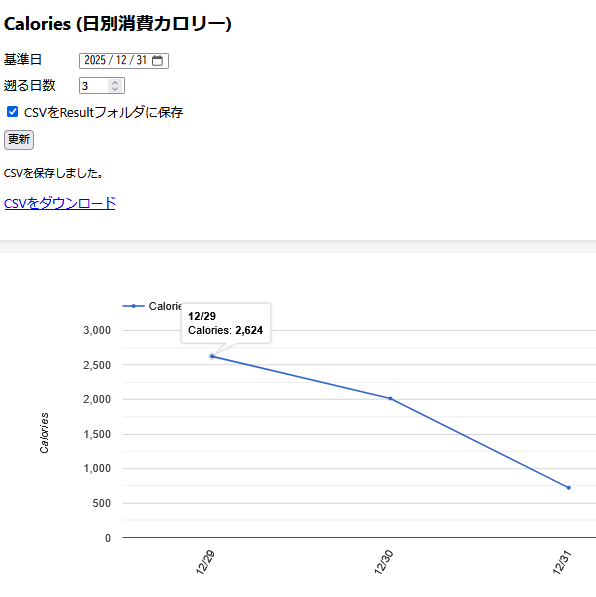
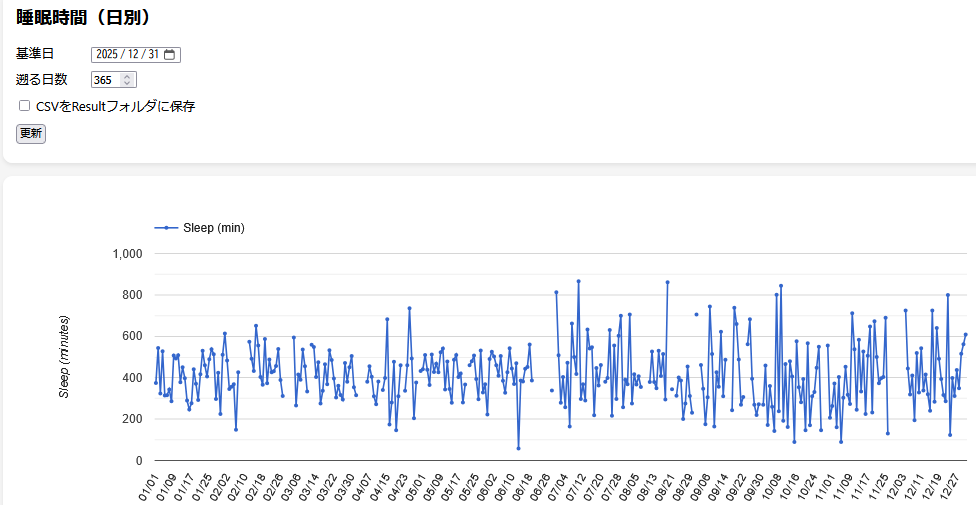
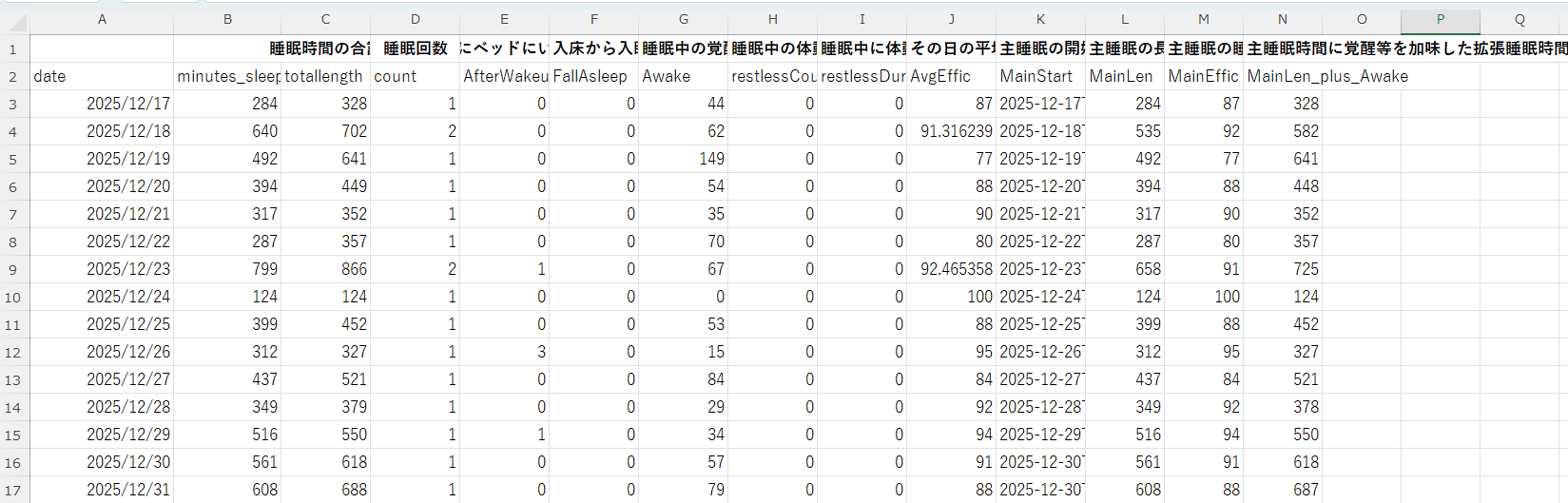
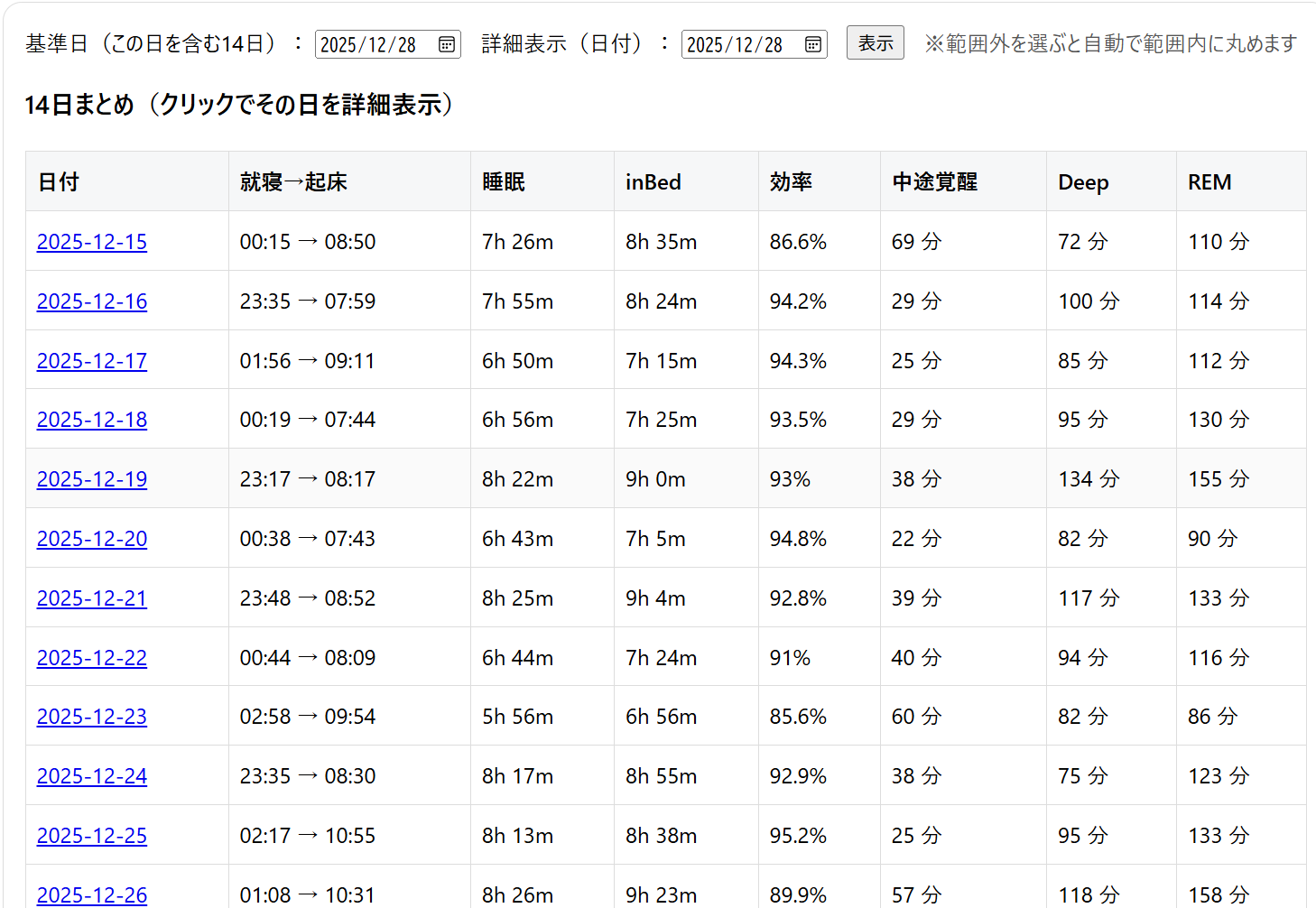
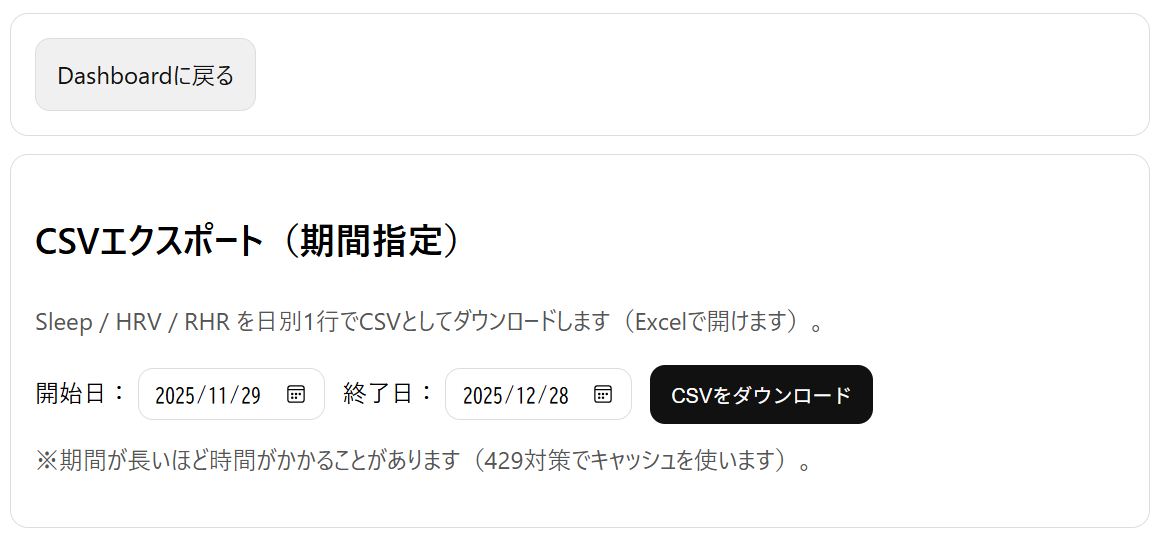
English:
“This server-based research application aims to support self-optimization of health behaviors by integrating Fitbit-derived physiological and behavioral data with an AI conversational agent. Participants can review visualized data on physical activity, sleep, heart rate variability, and resting heart rate, and receive personalized, dialogue-based feedback generated by an AI agent. The goal of this study is to promote awareness, reflection, and sustainable improvement of daily health behaviors and well-being.”
日本語:
「本サーバアプリケーションは,Fitbitから取得される生理・行動データとAIエージェントによる対話型フィードバックを統合し,健康行動の自己最適化を支援することを目的としています.参加者は,身体活動,睡眠,心拍変動,安静時心拍数などの指標を可視化して確認し,AIエージェントから個別化された助言を受ける.本研究の目的は,日常生活における気づきとフィードバックを促し,持続可能な健康行動およびWell-beingの向上を支援することです.」
Terms of Service
1. Purpose:
This service is provided for academic research conducted at Bunkyo Gakuin University. The purpose of this study is to examine self-optimization of health behaviors by integrating Fitbit-derived physiological and behavioral data with AI-based personalized feedback.
2. Eligibility:
Participation is voluntary. Only registered participants who have provided informed consent approved by the university ethics committee may use this service.
3. Use of Data:
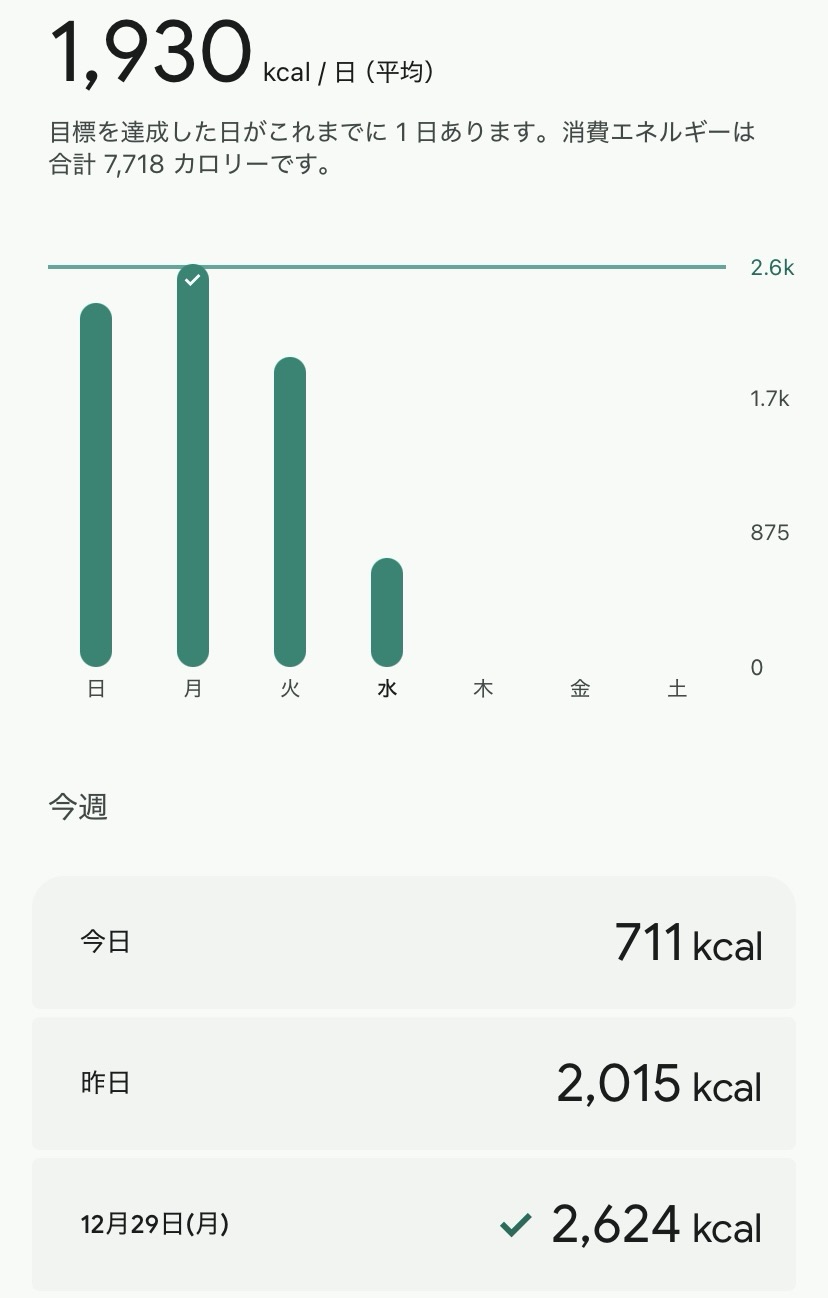
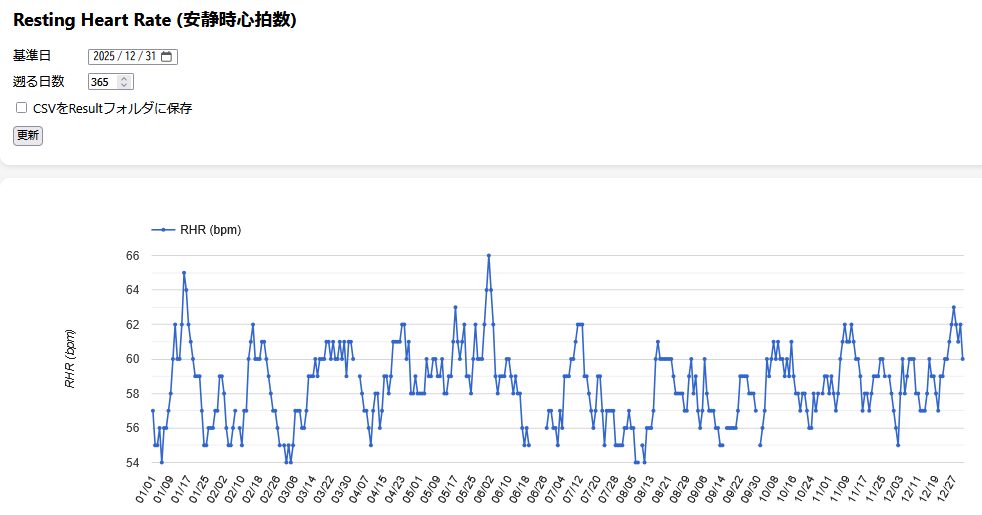
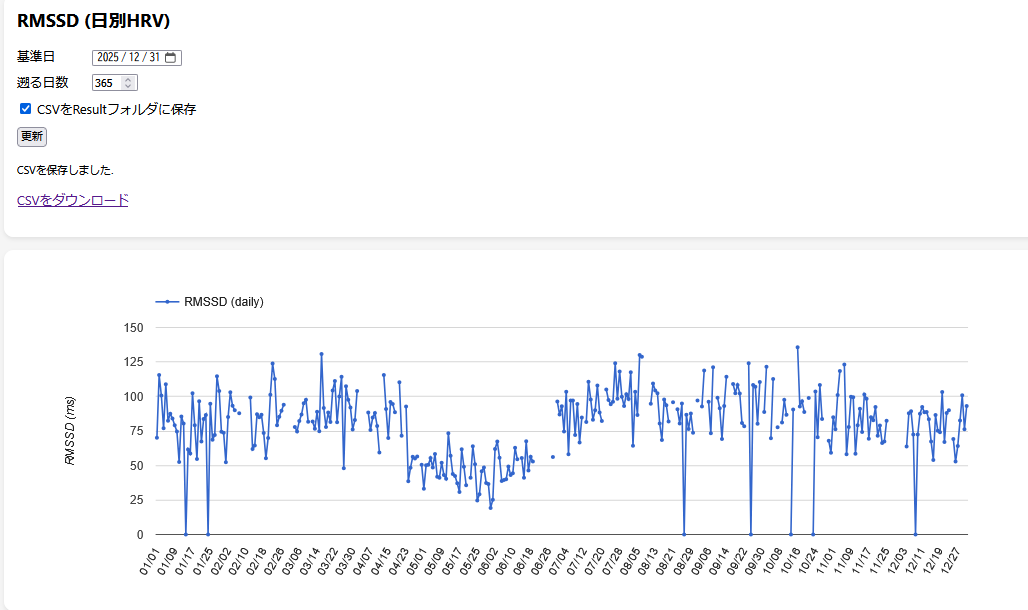
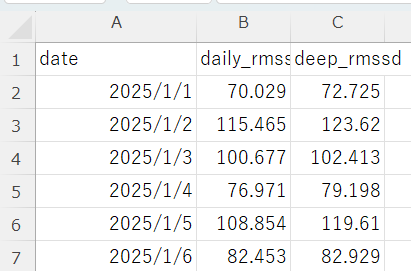
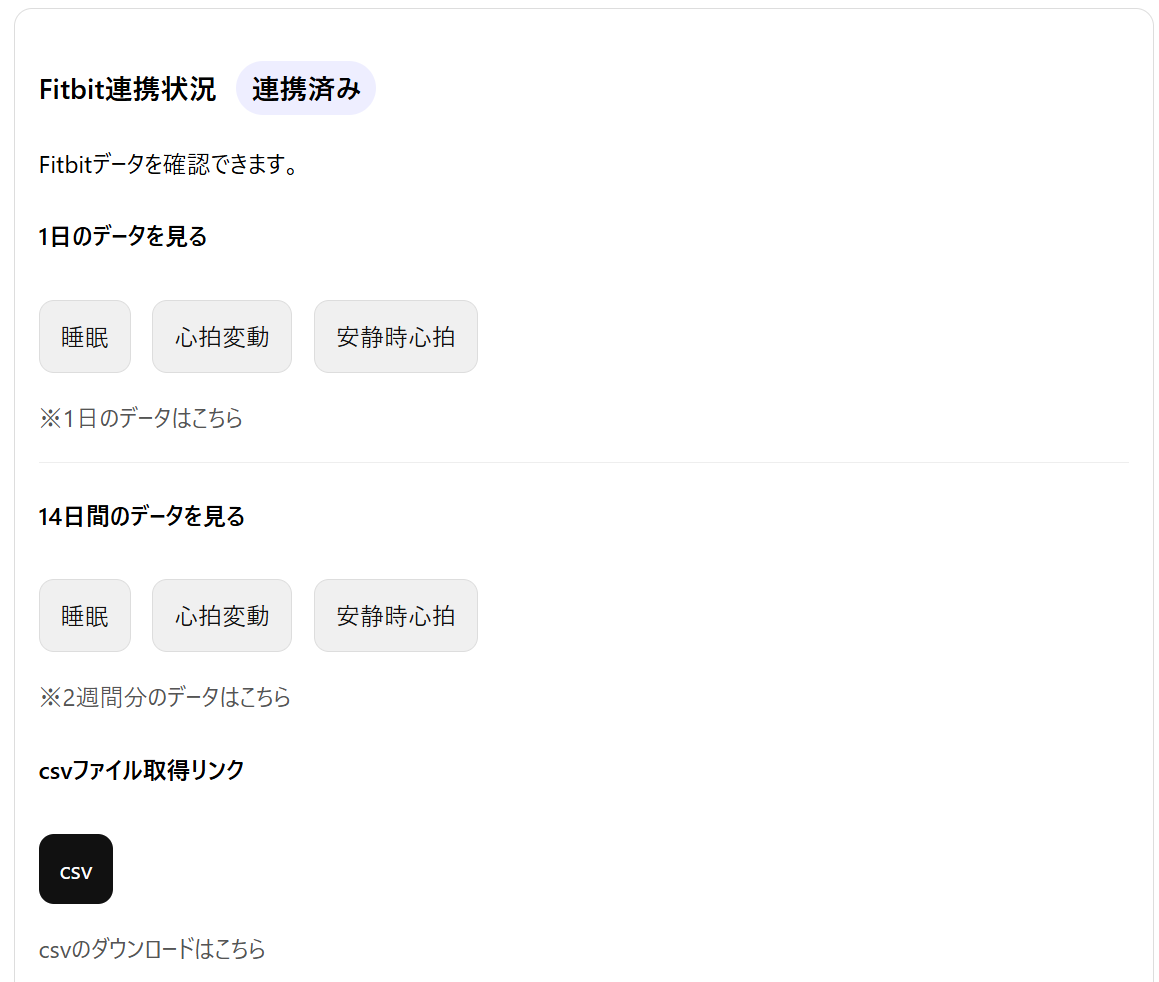
Data collected through this service, including Fitbit activity data, sleep data, heart rate variability, and resting heart rate, will be used solely for academic research purposes.
4. Responsibilities of Users:
Participants agree to provide accurate information and to use the system only for its intended research purpose. Any misuse of the system is prohibited.
5. Limitation of Liability:
This service is provided “as is” for research purposes. The research team is not responsible for any direct or indirect damages resulting from the use of this service.
6. Changes to Terms:
These terms may be updated in accordance with research needs and legal requirements. Participants will be notified of any significant changes.
利用規約
1. 目的
本サービスは,文京学院大学における学術研究のために提供されます.本研究の目的は,Fitbitから得られる生理・行動データとAIによる個別化フィードバックを統合し,健康行動の自己最適化について検討することです.
2. 対象
参加は任意です.大学倫理審査委員会の承認を受けた研究に対し,事前にインフォームドコンセントに同意した登録参加者のみが利用できます.
3. データの利用
本サービスを通じて収集されるFitbitの活動量,睡眠,心拍変動,安静時心拍数などのデータは,学術研究目的にのみ使用されます.
4. ユーザーの責任
参加者は正確な情報を提供し,本サービスを研究目的の範囲内で利用することに同意します.不正利用は禁止されます.
5. 免責事項
本サービスは研究目的のために「現状のまま」提供されます.研究チームは本サービスの利用に起因する直接的または間接的な損害に対して責任を負いません.
6. 規約の変更
本規約は研究上の必要や法的要件に応じて改訂される場合があります.重要な変更がある場合は参加者に通知します.
Privacy Policy
1. Data Collected
We collect Fitbit-derived data including physical activity data(e.g., steps, active minutes, calories burned), sleep data(e.g., sleep duration, sleep efficiency, sleep stages),
heart rate, heart rate variability, resting heart rate,and intraday (24-hour) heart rate and activity data at aminute-level resolution, as well as application usage logs.
2. Purpose of Data Use
The collected data will be used exclusively for academic research to study self-optimization of health behaviors and to develop AI-based support systems for improving well-being.
3. Data Storage and Security
All data are stored securely on university servers hosted in Japan (Sakura Internet). Access is restricted to the research team. Data are encrypted and anonymized before analysis.
4. Data Sharing
No personal data will be shared with third parties. Only aggregated, anonymized results will be published in academic papers or presentations.
5. Participant Rights
Participants may withdraw from the study at any time. Upon withdrawal, their personal data will be deleted from the system.
6. Contact
For questions about data privacy, please contact the research team at Bunkyo Gakuin University.
プライバシーポリシー
1. 収集するデータ
本研究では,Fitbitから取得される身体活動データ(歩数,活動時間,消費カロリー等),睡眠データ(睡眠時間,睡眠効率,睡眠段階等),心拍数,心拍変動,安静時心拍数に加え,24時間の心拍数および活動量(日内変動データ)を分単位で収集します.
また,アプリケーションの利用ログも収集します.
2. データ利用の目的
収集したデータは,健康行動の自己最適化およびWell-being向上を目的としたAI支援システムの検討を行う学術研究にのみ利用されます.
3. データの保存と安全性
すべてのデータは日本国内の大学サーバ(さくらインターネット)に安全に保存されます.アクセスは研究チームに限定され,分析前にデータは暗号化・匿名化されます.
4. データの共有
個人データが第三者に提供されることはありません.学術論文や発表では匿名化・集計された結果のみが公表されます.
5. 参加者の権利
参加者はいつでも研究から撤退できます.撤退後はその個人データはシステムから削除されます.
6. 問い合わせ先
データプライバシーに関する質問は,文京学院大学の研究チームまでご連絡ください.