コミュニケーションに必要な認識はブラウザで行う時代に!
WebGL版AIエージェントの音声認識に試用しているWebGL Speechというアセットが動作しなくなり(ブラウザのセキュリティ強化のせい?)音声会話に支障が出ている。WebGL版OpenGLの遅さや、Web版Mediapipeの充実を鑑みるに、「CGなどUnityでしかできないものはWebGLに、音声や表情など各種認識はブラウザに」という機能の棲み分けが今後一般的になるのではないか!?コミュニケーションに必要な認識能力はブラウザに統合されるという時代の流れがあるとの読みだ。
音声認識
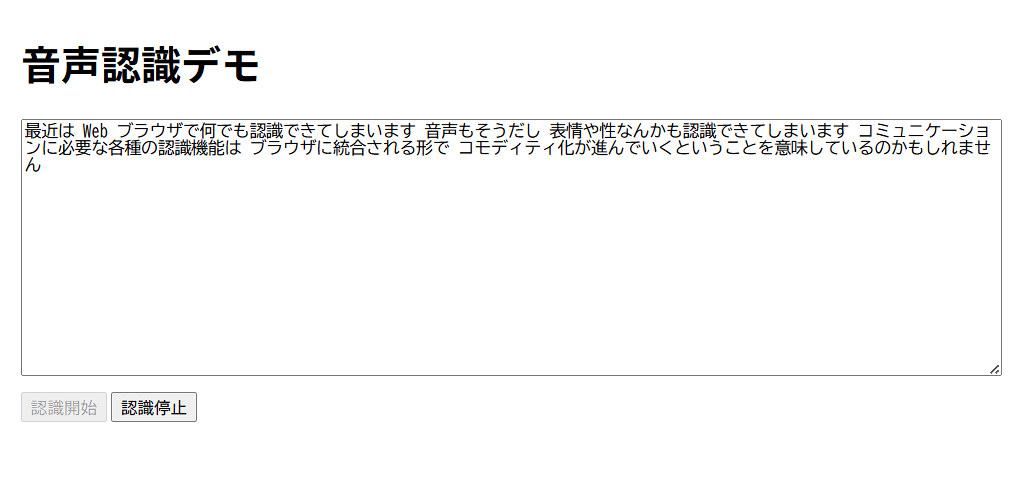
ちょいとo4miniに作成してもらう。「Web Speech API(webkitSpeechRecognition)でブラウザに表示したテキストエリアに、発話した内容を表示するデモプログラムを作成してくれませんか?Javascriptで」完成したデモは十分すぎる仕上がりだ。音声認識はブラウザで受けて、それをWebGLアプリで吸い上げる作戦だ。
表情認識
表情認識は、Googleのデモをベースにやはりo4miniに作成してもらう。こちらは少々苦戦したが、左右反転なしでFaceMeshも表示されるデモを作ってもらえた。
なによりも朗報なのは、iPadでも動作するということだろうか。

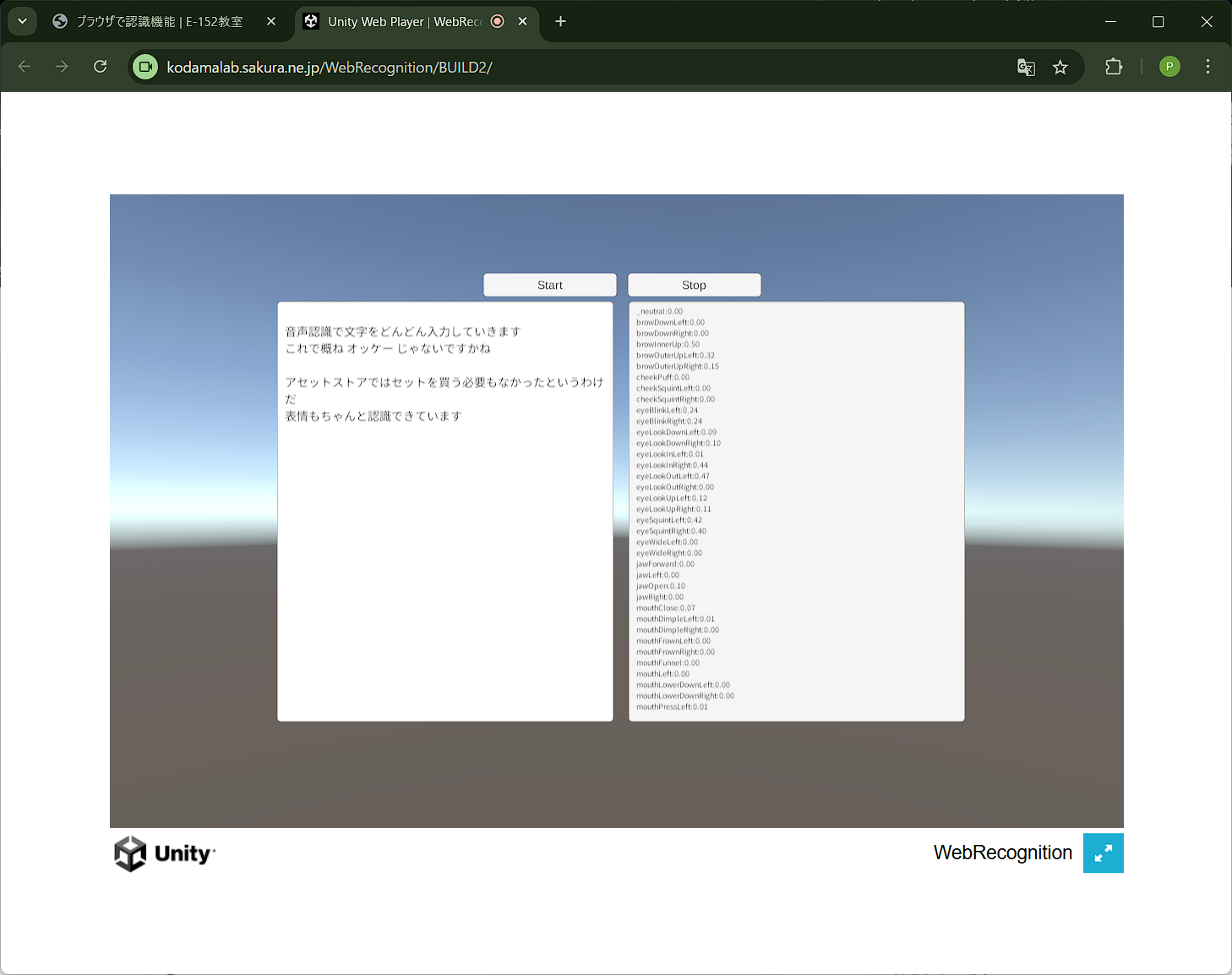
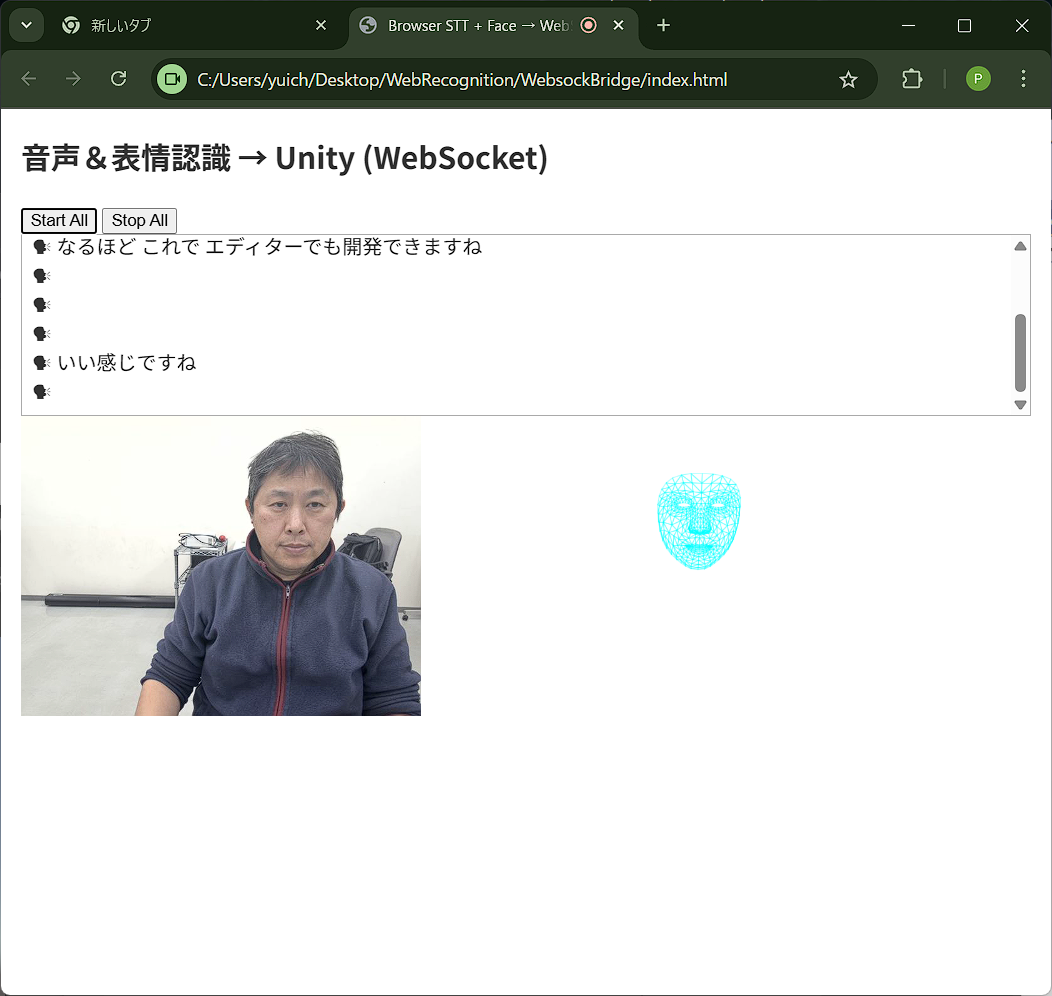
音声と表情をブラウザで同時に認識する
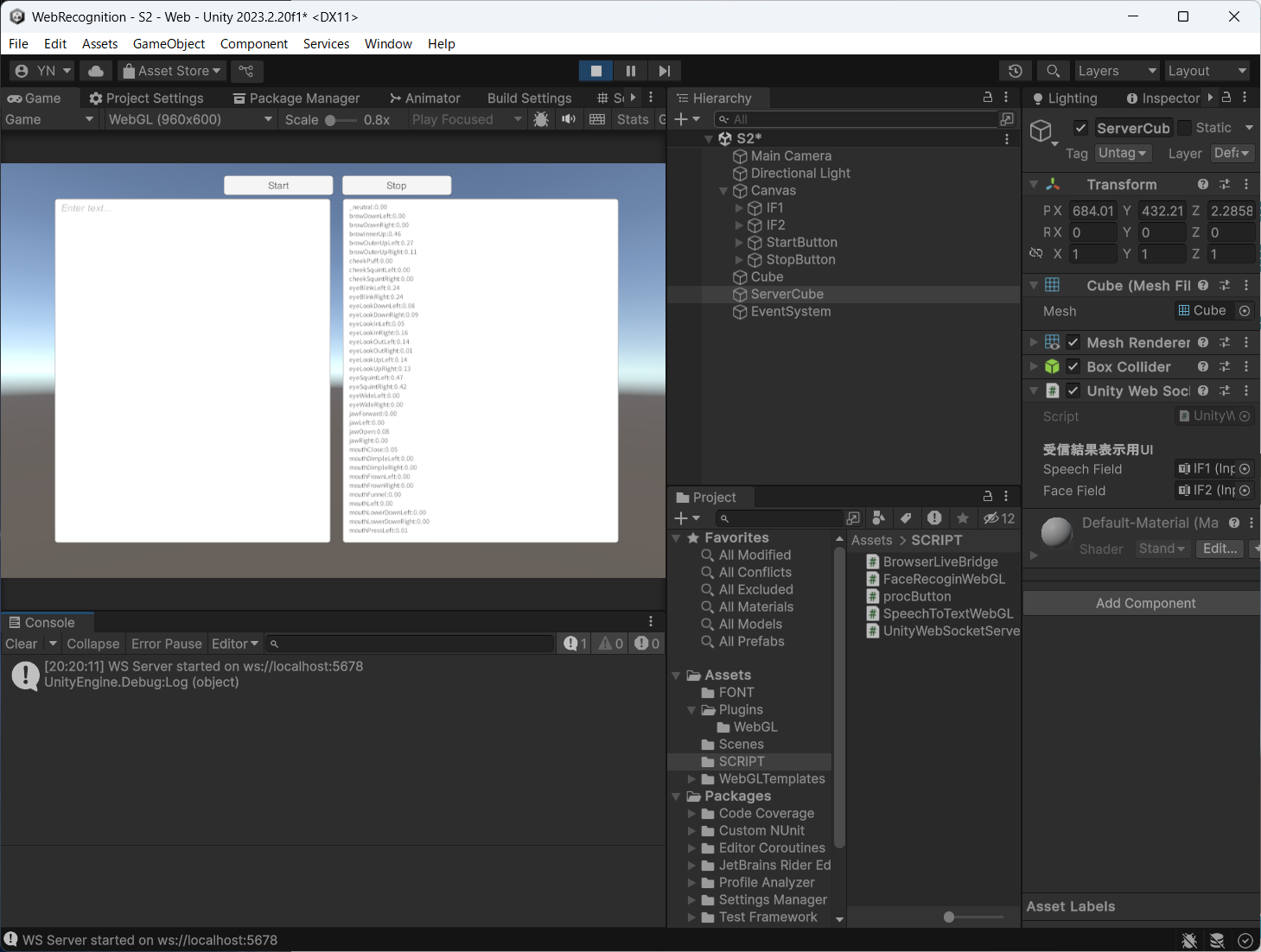
上記で作成したJSは,Unityのプラグインとして記述し,WebGLビルドに含めることができる。晴れて「ブラウザで認識した音声+表情をWebGLへ送る」アイデアが実現した。o3様々だ。しかし,デバッグするためにビルドする必要があるという問題が残る。Unityエディタで開発中は,ブラウザで認識した情報を受取ることはできないの?o3曰く,Websocketを使えば良い。そのためには,Websocket-sharpが必要とのこと。これで開発中も音声+表情認識が無事に使えるようになった。やった!!o3の使用制限はあと24回になっちゃったけど。
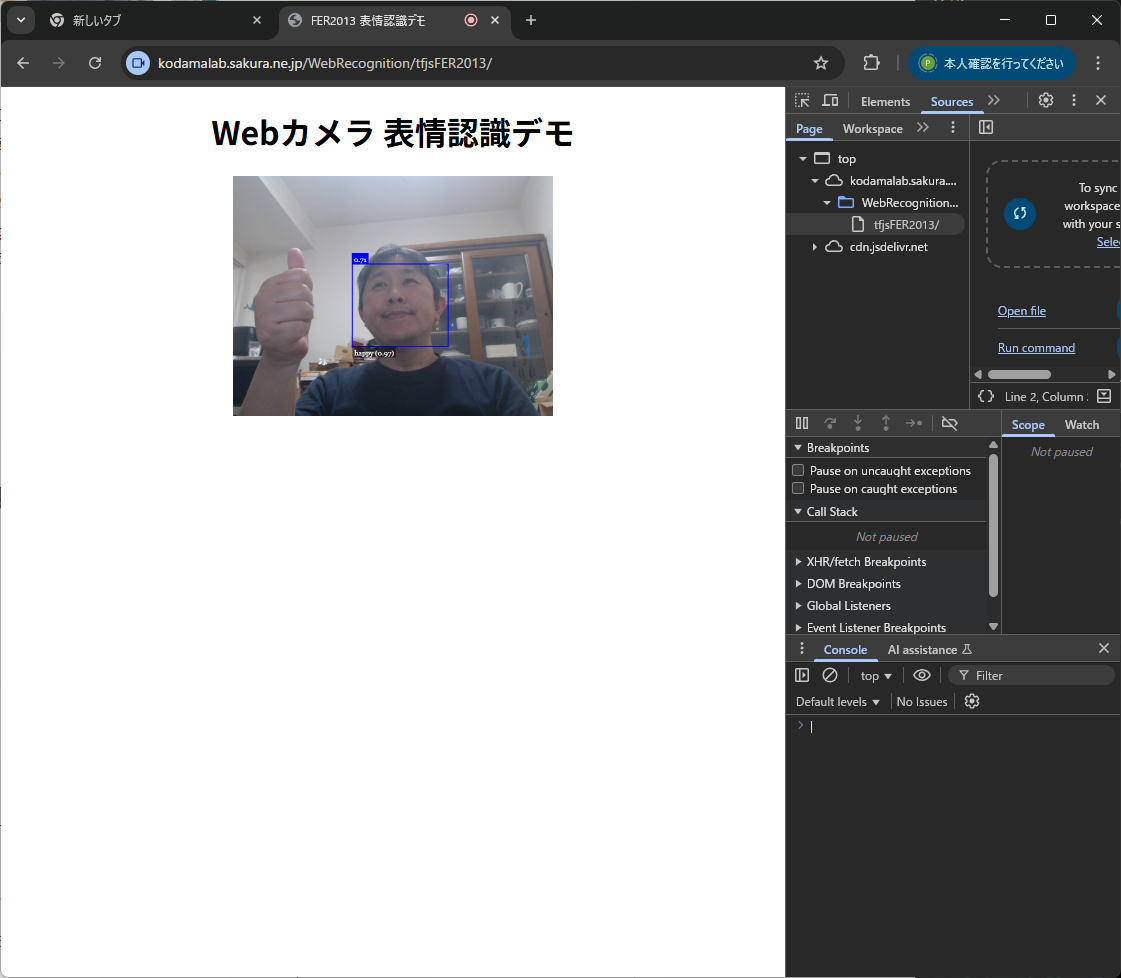
ブラウザでFER2013を動かす
MediaPipeがJSで動いて、その結果をUnityWebGLに呼び込めるなら、OpenCVで使っていたFER2013モデルも読み込めないのだろうか?これは、TensorFlows.jsというものがあり、そのラッパーであるface-api.jsを利用すれば良いようだ。モデルをDLして配置して、エラーを見ながらo4-miniに相談すると、無事ブラウザで動かすことに成功した。楽しい~!これもアリですね。
一連の会話
ブラウザでFER2013動かすデモ