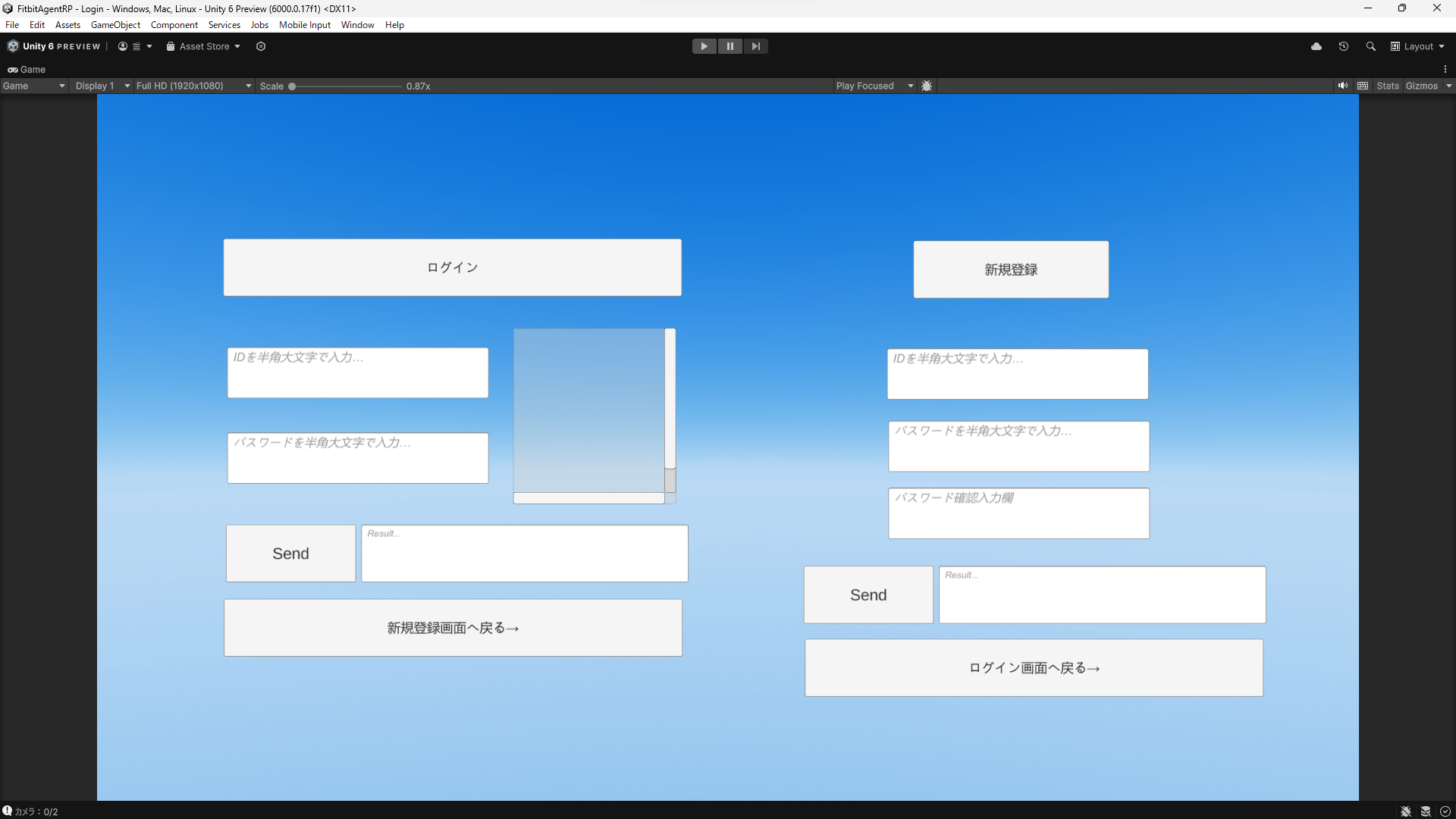
UezoさんのChatdollkitを見て気がつく。まえにもBard使ってたけど、かなり賢いGeminiがなんと使い放題らしい。人格も維持し、JSON出力もキープしてくれる。これはひょっとして・・・。Unityから使う方法も一応紹介されている。もっと簡単に使える方法はないものか。。
C#でAIと無料で会話できるようにしてみた
これとか良いのではないか・・・。dllが必要!?
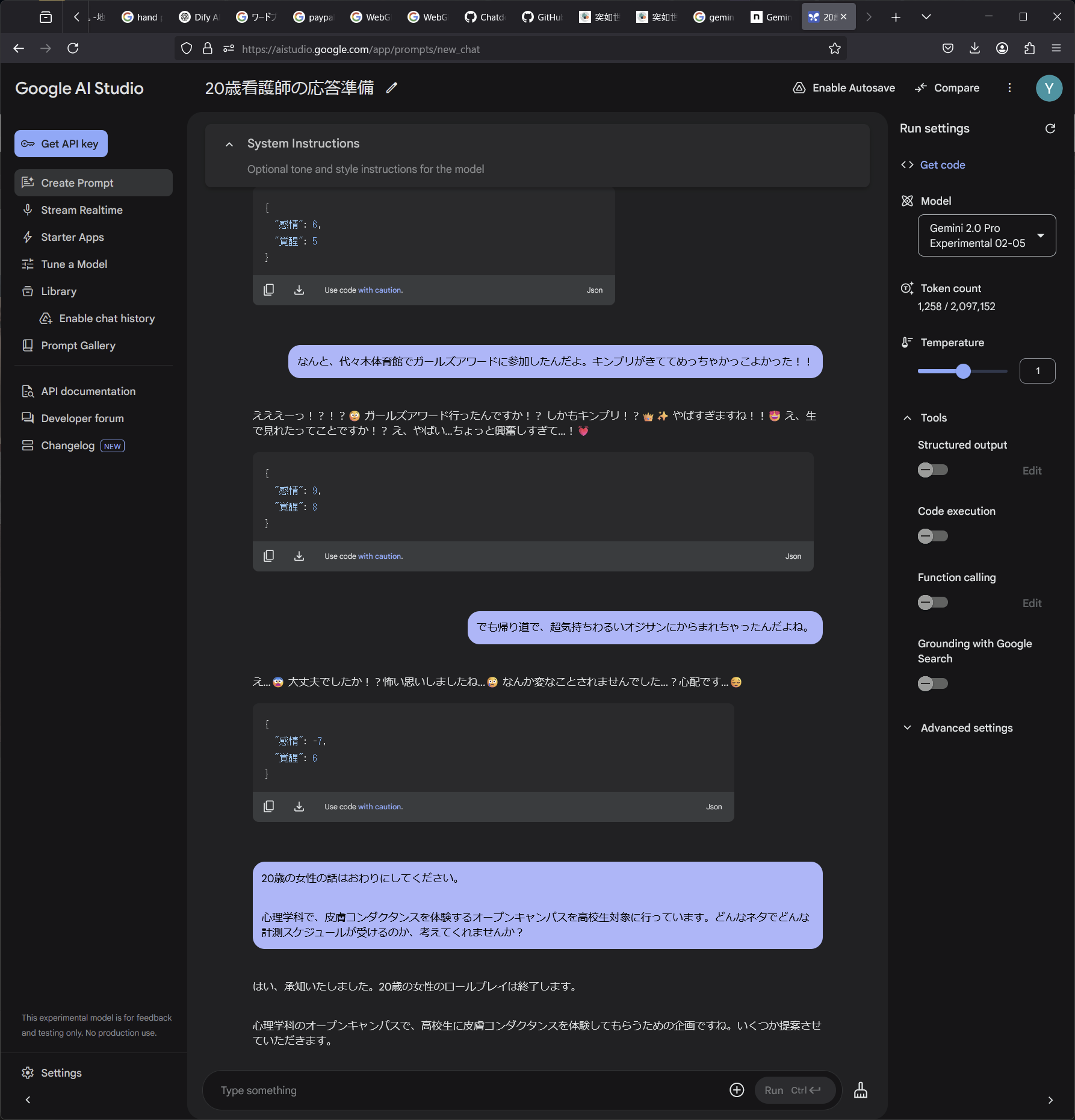
GASを使うと3分でできるというが・・・。めんどくさい。やるしかないのか。
Gemini↔️GAS↔️UnityでGeminiを使ってみる(テキスト編)
Geminiは、ChatGPTにUnityでの使い方を聞いたらあっさり動作した。・・・がしかし、50リクエスト/日とある。50リクエストしかできないって事じゃ??はぁ~


using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using UnityEngine.Networking;
using TMPro;
using UnityEngine.UI;
public class GeminiChat : MonoBehaviour
{
public string apiKey = ""; // あなたのGemini APIキー
public TextMeshProUGUI outputText;
public InputField IF1;
public Text outputmessage;
private List<Content> conversationHistory = new List<Content>(); // 会話履歴(最大100)
void Start()
{
// 初期化時は空の会話でもOK
}
public void procMessage(string message)
{
string userInput = IF1.text;
if (!string.IsNullOrEmpty(userInput))
{
AddToHistory("user", userInput); // ユーザー発言を履歴に追加
StartCoroutine(SendRequestToGemini());
}
}
void AddToHistory(string role, string text)
{
// Gemini APIのフォーマットは content[].parts[].text を使用
Content content = new Content
{
role = role,
parts = new Part[]
{
new Part { text = text }
}
};
conversationHistory.Add(content);
// 最大100件までに制限(roleごとではなく全体で100)
if (conversationHistory.Count > 100)
{
conversationHistory.RemoveAt(0);
}
}
IEnumerator SendRequestToGemini()
{
string url = "https://generativelanguage.googleapis.com/v1beta/models/gemini-2.0-pro-exp-02-05:generateContent?key=" + apiKey;
GeminiRequest requestData = new GeminiRequest
{
contents = conversationHistory.ToArray()
};
string jsonData = JsonUtility.ToJson(requestData, true);
byte[] postData = System.Text.Encoding.UTF8.GetBytes(jsonData);
UnityWebRequest request = new UnityWebRequest(url, "POST");
request.uploadHandler = new UploadHandlerRaw(postData);
request.downloadHandler = new DownloadHandlerBuffer();
request.SetRequestHeader("Content-Type", "application/json");
yield return request.SendWebRequest();
if (request.result == UnityWebRequest.Result.Success)
{
string result = request.downloadHandler.text;
GeminiResponse response = JsonUtility.FromJson<GeminiResponse>(result);
string reply = response.candidates[0].content.parts[0].text;
Debug.Log("Gemini Response: " + reply);
if (outputText != null)
outputText.text = reply;
outputmessage.text = reply;
// AIの返答を履歴に追加(role: "model")
AddToHistory("model", reply);
}
else
{
Debug.LogError("Gemini API Error: " + request.error);
outputmessage.text = request.error;
}
}
// JSON構造(Gemini API仕様)
[System.Serializable]
public class GeminiRequest
{
public Content[] contents;
}
[System.Serializable]
public class Content
{
public string role; // "user" or "model"
public Part[] parts;
}
[System.Serializable]
public class Part
{
public string text;
}
[System.Serializable]
public class GeminiResponse
{
public Candidate[] candidates;
}
[System.Serializable]
public class Candidate
{
public Content content;
}
}