PowerAutomate基本
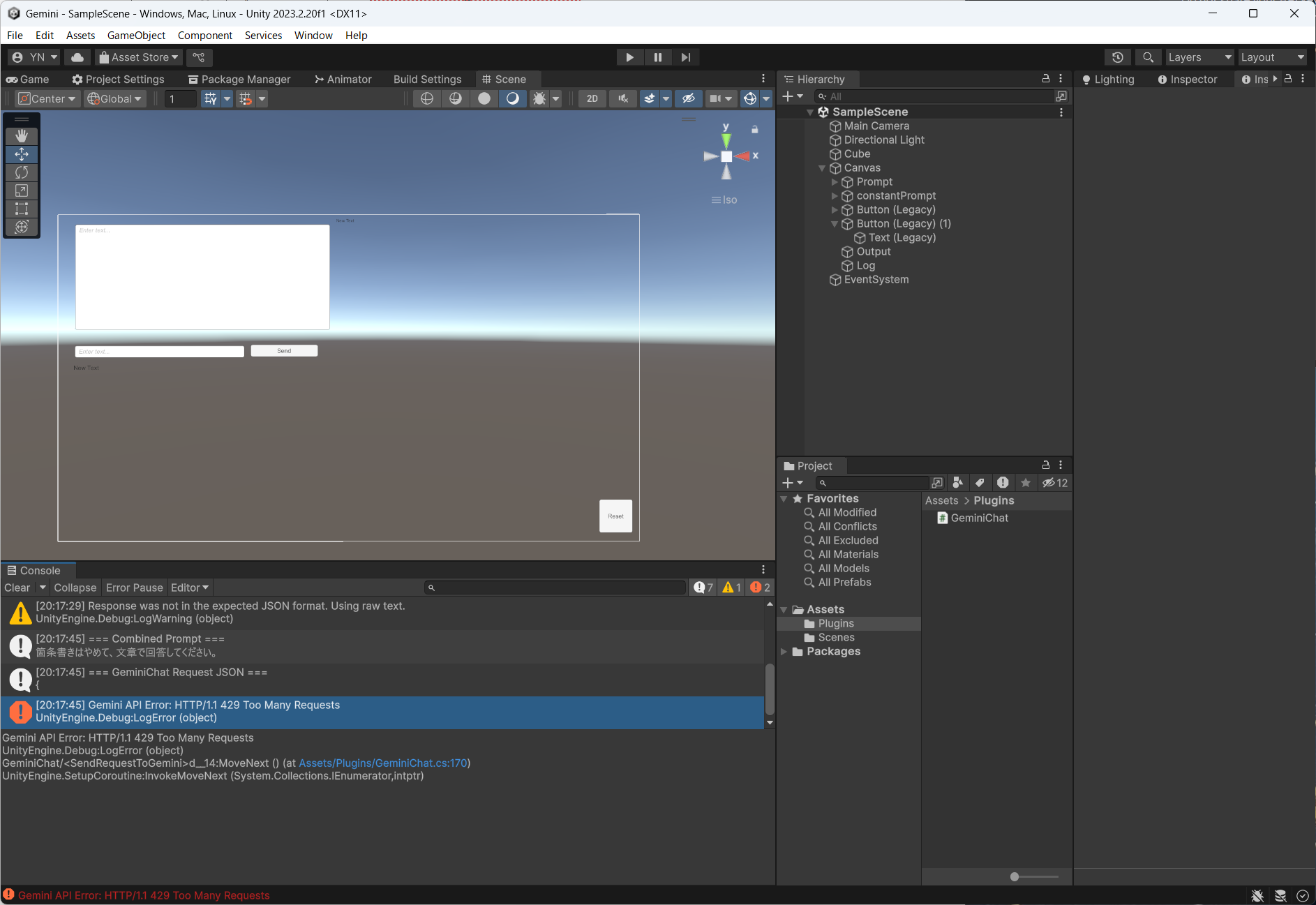
これに従って学んでみよう・・・Power Automate使い方ガイドなんてのもある。フォームはできた。SharePointリストの細かい使い方 学びの渦に飲み込まれるあるある・・・Listは使えるようだね。SharePointからでもいいし、Teamsからでも作れると。エクセルデータを読み込むこともできる。・・・リストは、Teamsから作ったものがPAから認識できる。Formsの結果をListに保存し、担当者にメール&Teams投稿でアナウンスまではできた。さて、PDF(ワード?)は作れるのかな?独自ルールが多すぎて、つまづきポイントがありすぎる。MSのこういうところは相変わらずだなー。
フォーム入力からワード文章を作る
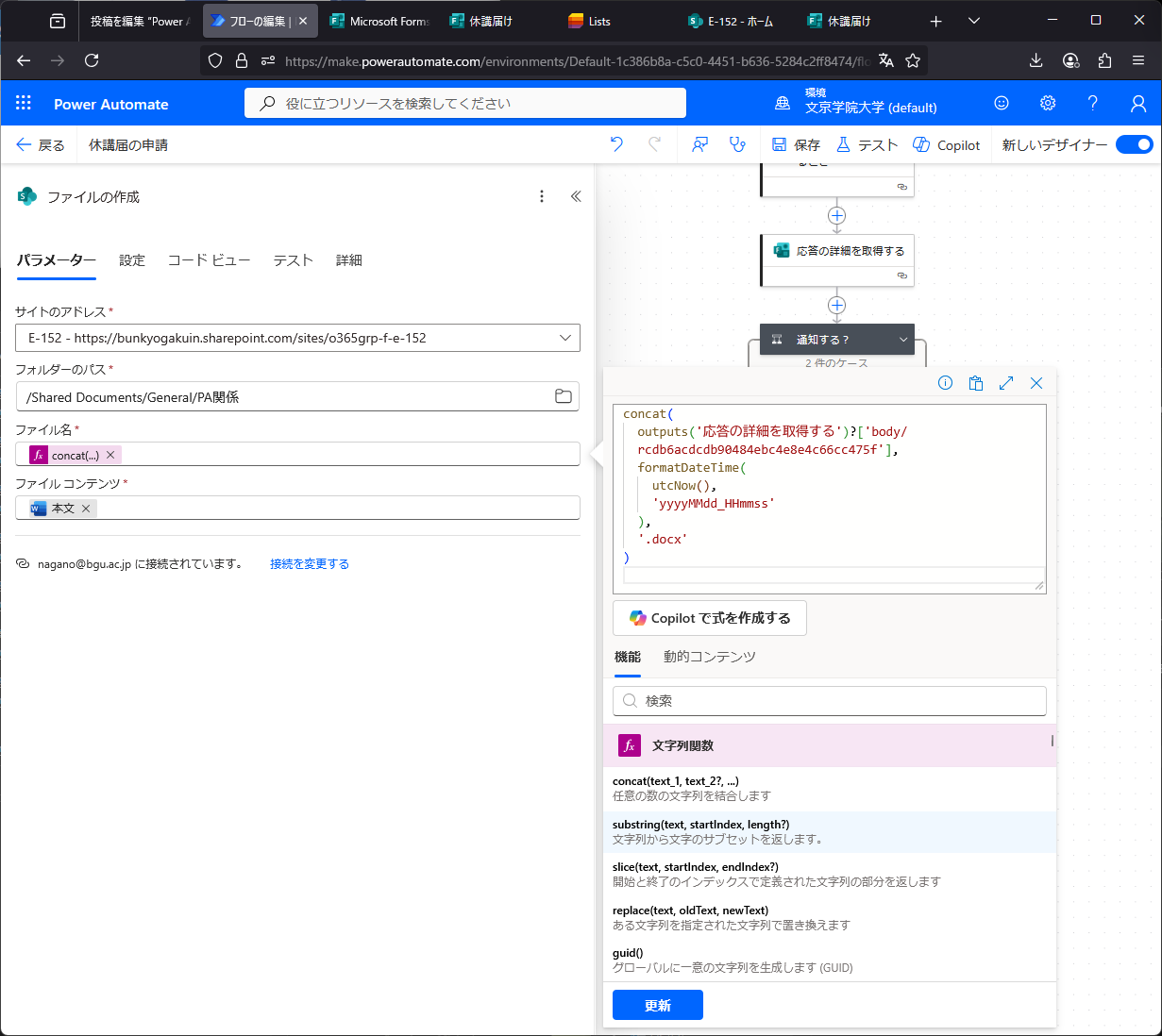
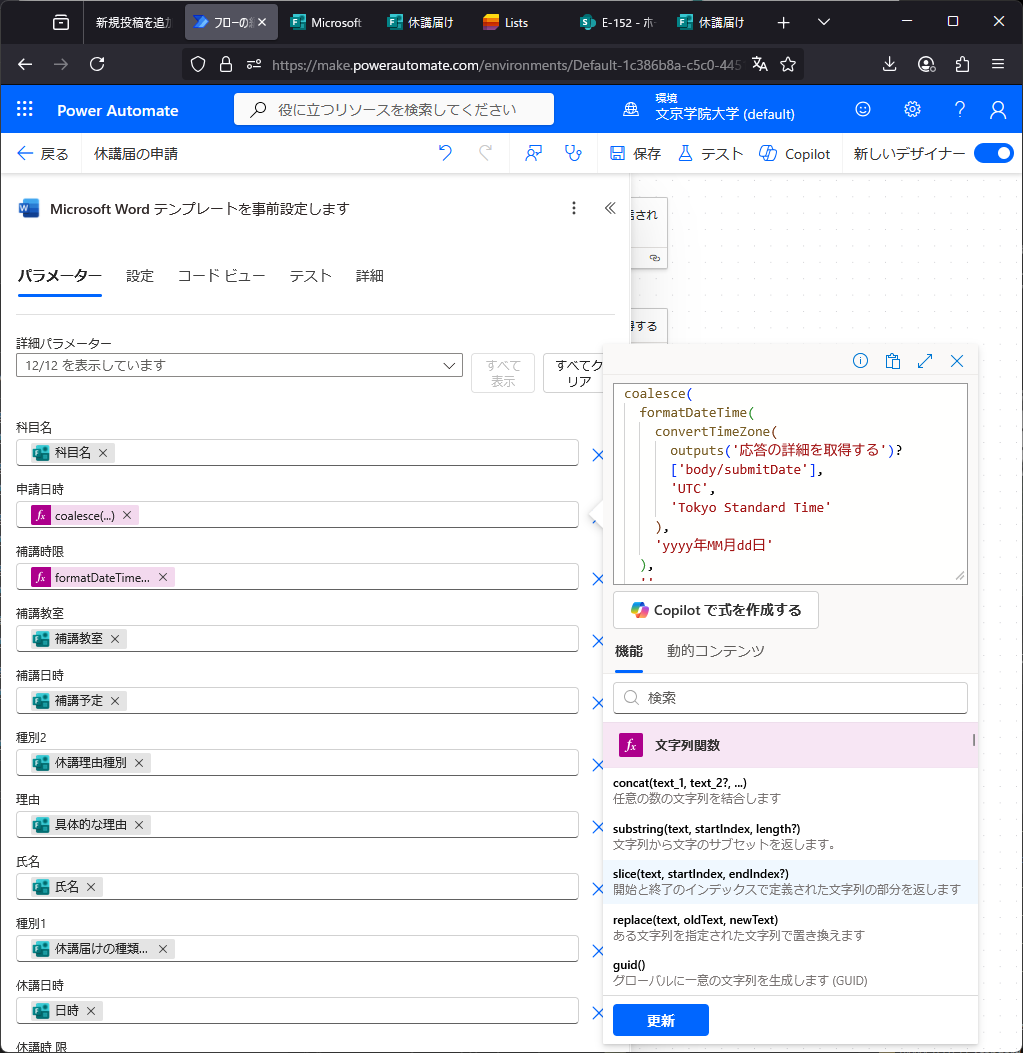
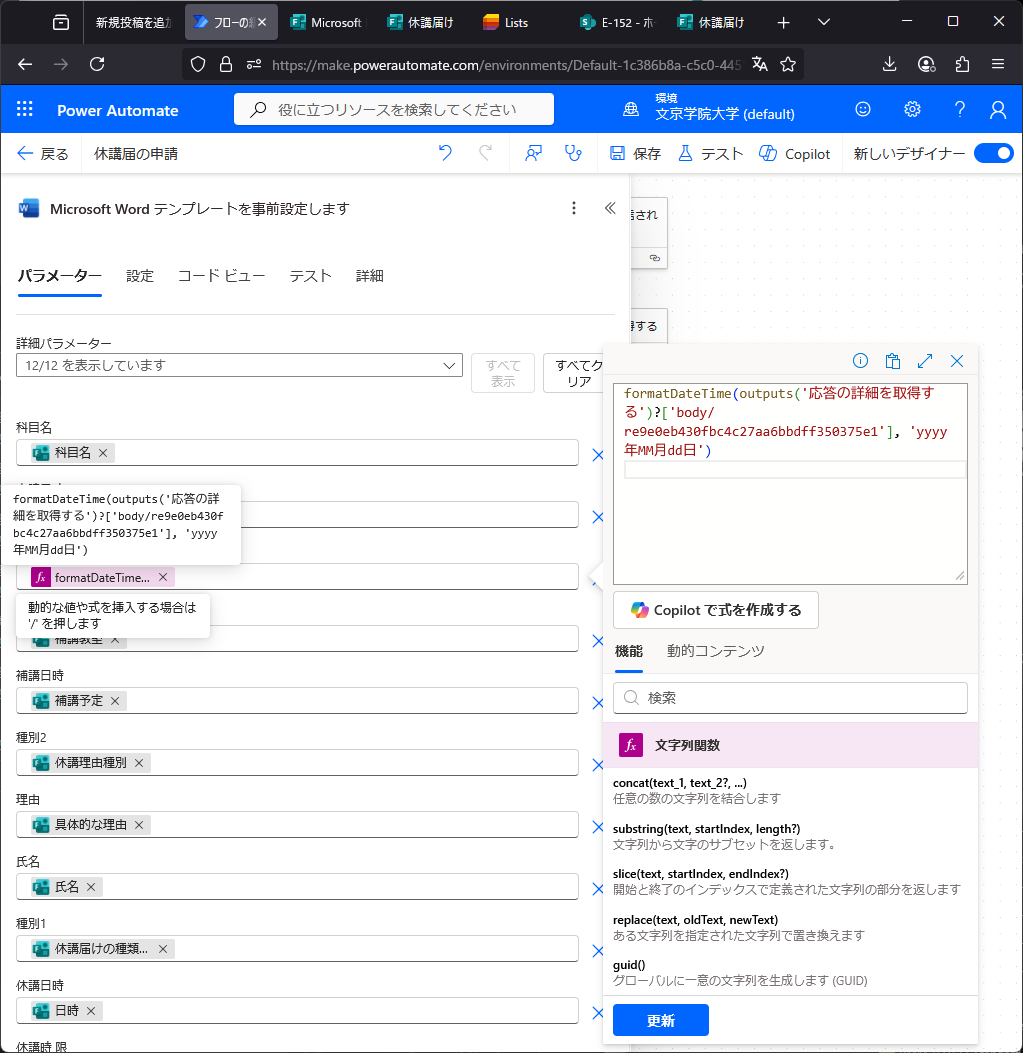
ワード文章をつくるか。差し込み印刷用のテンプレート作成?(涙)ここを参考にやってみるか。。なるほど、(1)差し込み印刷用テンプレートを作成し、(2)Excelやフォームからデータを読み込んではめ込み、(3)SharePointに作成する、という手順だね。確認できた。さらに、フォームで入力した内容からTeams上に休講届を作ることができた。日付なども入力できるがフォーマットが気に入らないこともある。FXから式を入力できるが、フォームから取得できる値はツールチップで確認するのが良い。コメントアウトは出来ず(マジ!?)不必要な処理は条件分岐で1=2などの式を入れfalseにする。これ本当に便利なのか?ああ、もうこんな事覚えて何になるんだよ、時間返せよ。ちなみにPowerAutomateのワード作成機能はPremiumモードに契約してないと使えないので、3ヶ月でお試し期間が切れる。

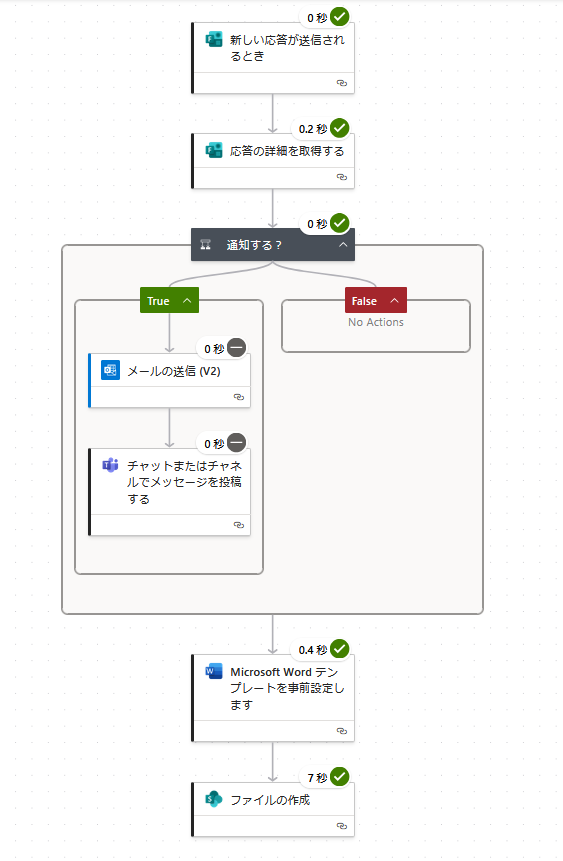
承認プロセスを挟む
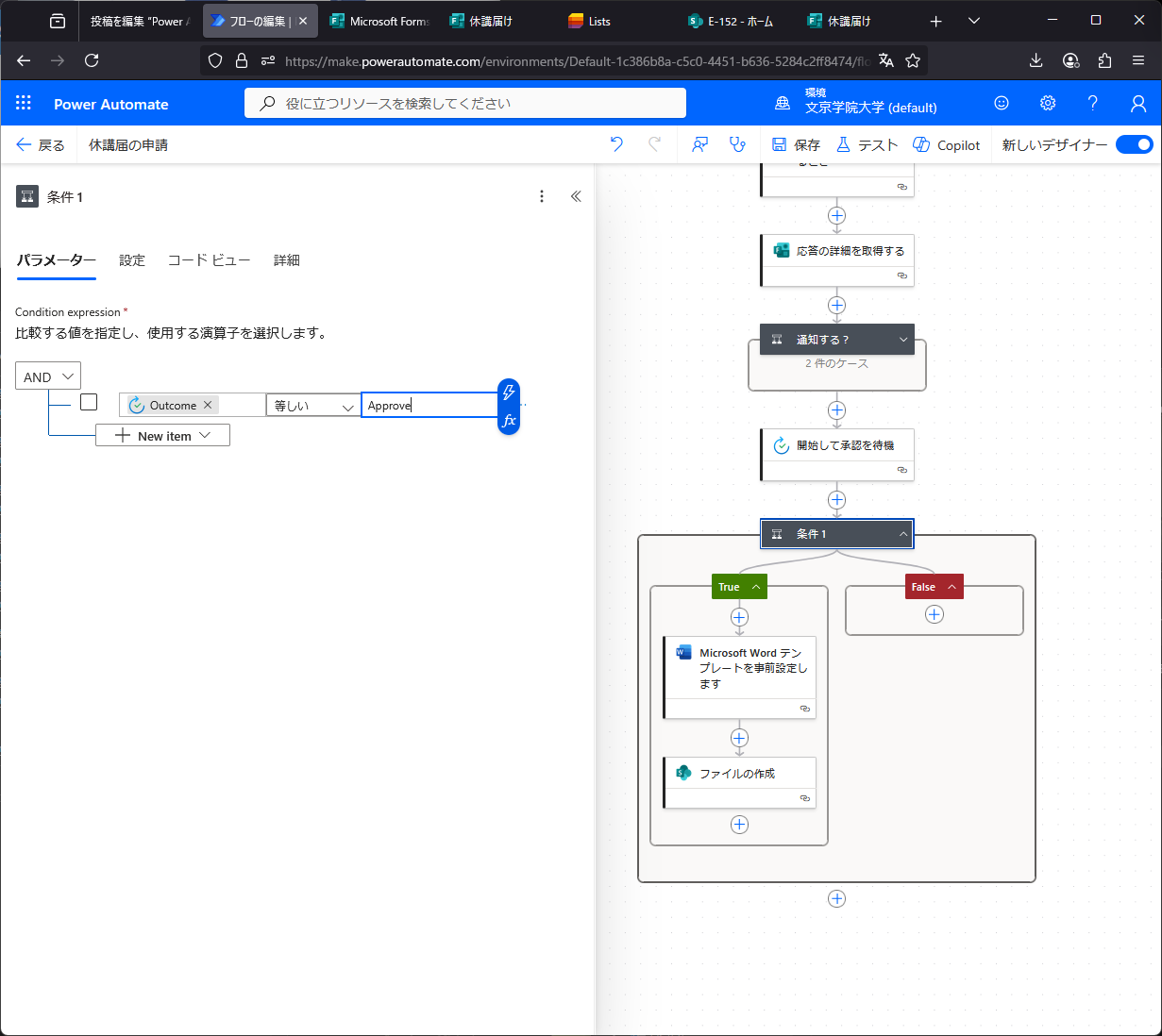
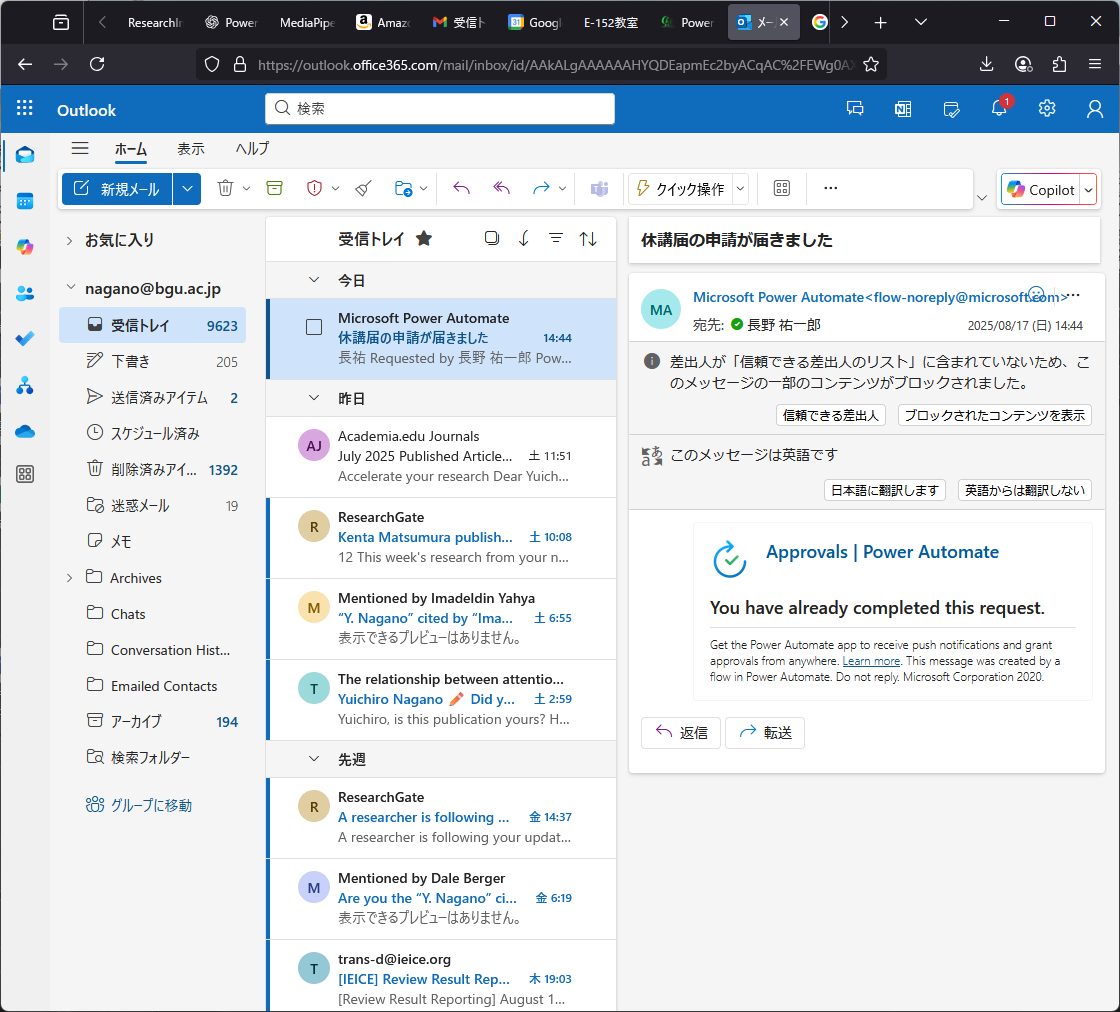
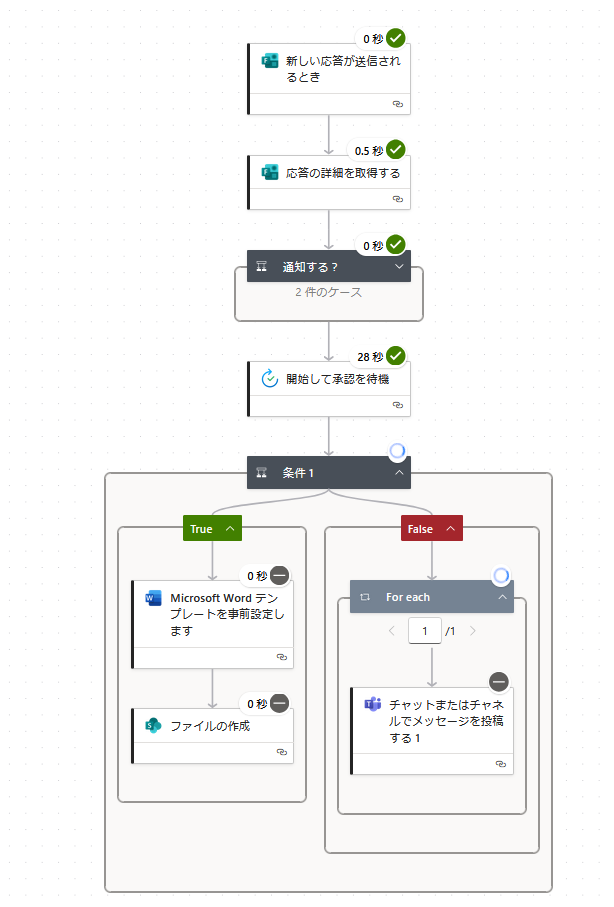
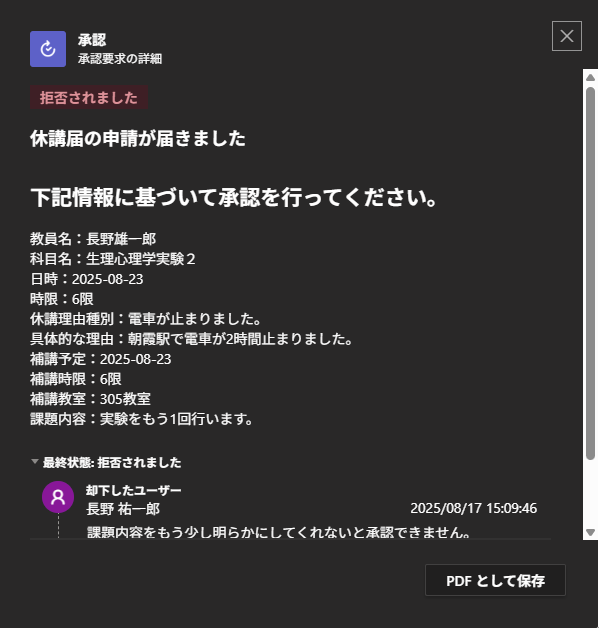
フォームで入力、自動で書類作成はできそうだが、不備がある場合にどうするか。Power Automate には 「承認の作成(Start and wait for an approval)」 というアクションがあるらしい。なるほど、「開始して承認を待機」で、条件分岐でOutcomeを拾うんだね。承認者が複数いて、誰か1人でも承認すればOKなときは、「承認/拒否 – 最初に応答」で良い。承認はメールとTeamsに来る。不承認の場合は、承認画面からメッセージを入れて不承認すると「拒否されました」旨の通知とメッセージが表示される。しかし、もう一回フォーム入力するの事実上無理でしょう・・・。どうすりゃいいの。