プロジェクトはWindowsネイティブアプリ用に
WebGLアプリはUDPで表情認識AIの情報受け取れないし・・・一体どうしたらよいのか。結局,WebGL版の模擬人格プロジェクトをコピーして,Windowsネイティブアプリにしてビルドしてみたら,意外に良い感じで動いたので,こちらで行くことにしました。プロジェクトの名前はNative6です。ビルドターゲットのスイッチは7分弱かかって,頻繁に行うのは現実的じゃないです。
表情データの送信方式
遅きに失した感もありますが,オープンCVで認識した感情データをudpで送る部分はすでにできていたので,後はAIの情報を受け取るプログラムをGPT4oに作成してもらい,そこから感情情報を抜き出し,コミュニケーションに加味できるように,調整してみました。
実際に動かしてみて
感想としては,感情認識のタイミングがOpenAIへの問い合わせ依存なので,ややテンポが遅いようにも感じる。しかし現実のコミュニケーションも案外こんなもんかもしれない。
1.リアルタイムで感情模倣が起こることが大切なのか
2.GPT4oにこちらの感情状態が伝わることが大切なのか
どちらにしても表情を合わせてくれるので,これらの要因が実際のコミュニケーションでどんな風に機能するのかまだよくわからない。生きた人間のコミュニケーションでは,相手の(時として細やかな)表情を瞬時に読み取り,相手の意図や,コミュニケーション内容の真偽を直感的に評定していたりする。こういったコミュニケーションがAIエージェントに果たして可能なのか,そもそも必要なのか,研究はまだ始まったばかりだから分からないことだらけだ。
PsychoPy+Processing#01
PsychoPyと外部プログラムの連携
ここでは,下記のようなシンプルな実験プロジェクトに外部プログラムで測定した測定結果をUDPで送り込み保存してみる。プロジェクトは,Fixation(+)の後にTarget(□)が出るので,スペースキーを押すと,反応時間が記録されるというもの。
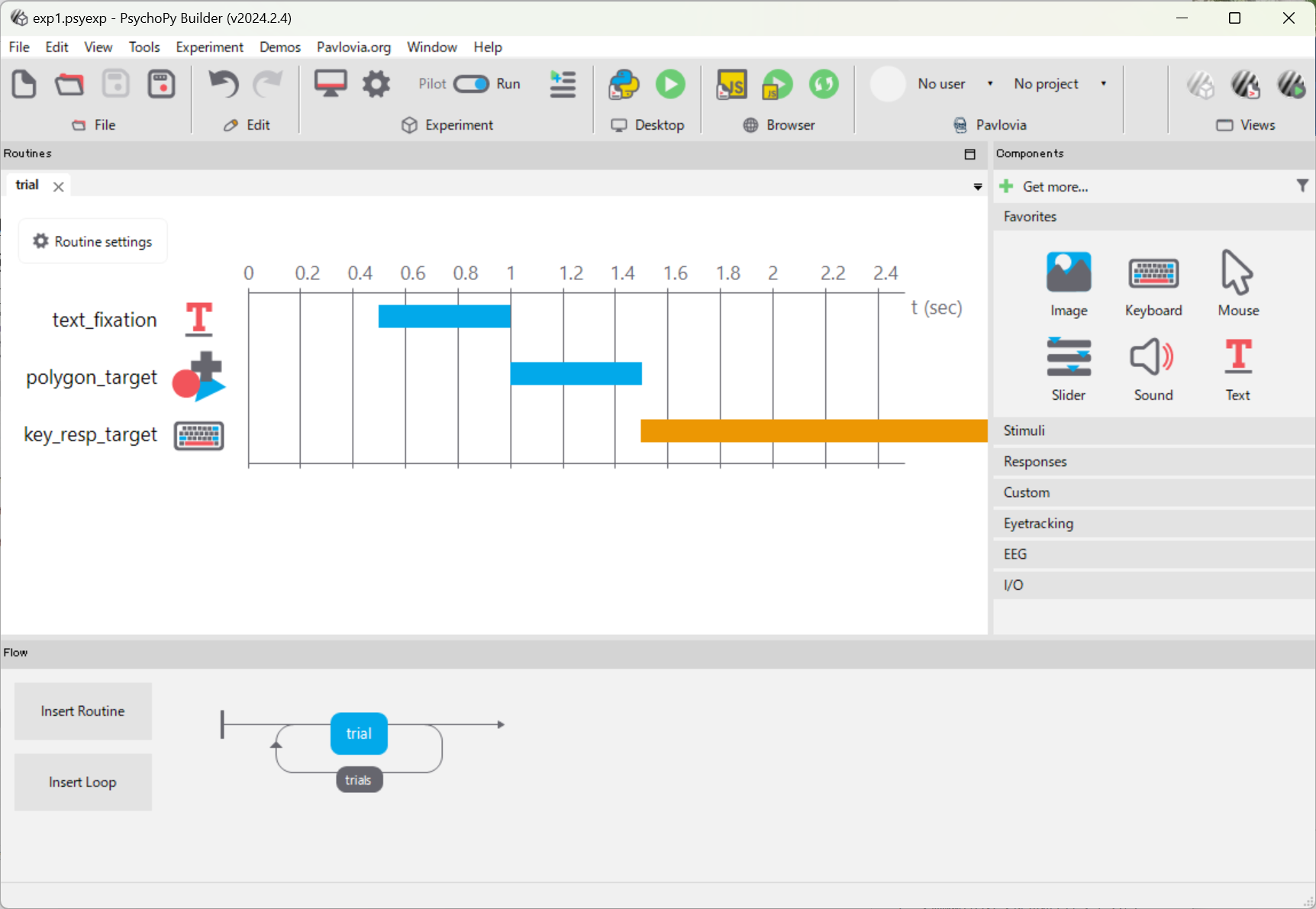
BuilderのPythonマーク(青と黄のヘビ)をクリックすると,Coderが起動する。ここでコードを改造すると,UnityやProcessingからのデータを受け取ることができる。ただし,Builderでコードを生成すると,改造部分はすべて消し飛ぶので注意が必要だ。
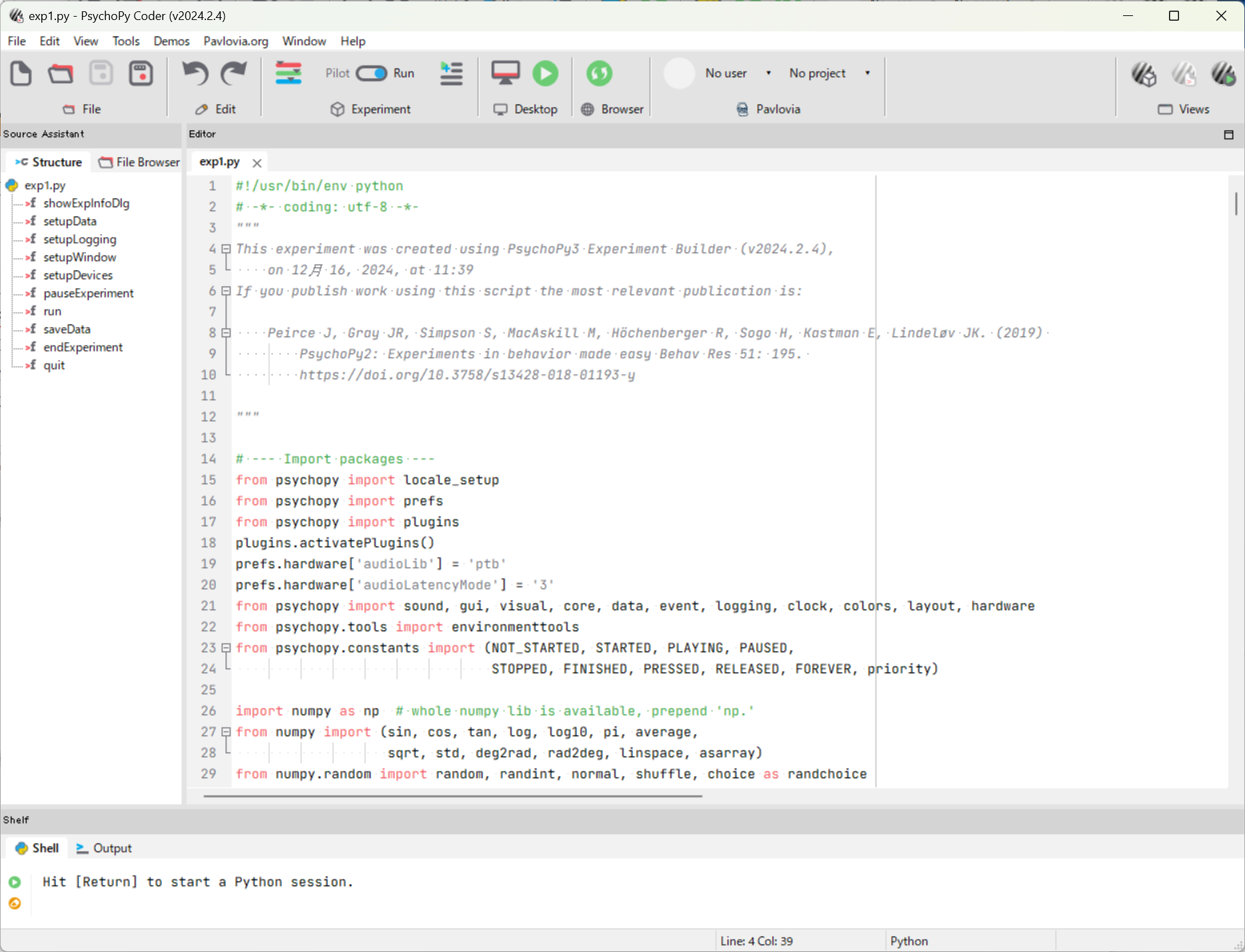
まず冒頭で,ライブラリを呼んで,グローバル変数とUDPでデータを受け取るサブルーチンを用意する。
############# NAGANO #################
import socket
import threading
# UDPソケット設定
UDP_IP = "127.0.0.1" # 受信するIPアドレス
UDP_PORT = 5005 # ポート番号
# グローバル変数に最新のUDPデータを格納
latest_udp_data = "No Data"
def udp_listener():
"""非同期でUDPデータを受信する関数"""
global latest_udp_data
sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
sock.bind((UDP_IP, UDP_PORT))
while True:
data, addr = sock.recvfrom(1024) # 1024バイトまで受信
latest_udp_data = data.decode("utf-8") # デコードして文字列に
############# NAGANO #################
次にプログラム開始部分でスレッドをスタートする。
win = setupWindow(expInfo=expInfo)
setupDevices(expInfo=expInfo, thisExp=thisExp, win=win)
############# NAGANO #################
# UDPリスナーをスレッドで起動
udp_thread = threading.Thread(target=udp_listener, daemon=True)
udp_thread.start()
############# NAGANO #################
でさらに,UDPでうけとったデータを保存する。データの受取は,別スレッドが非同期で行ってくれる。
key_resp_target.duration = _key_resp_target_allKeys[-1].duration
############# NAGANO #################
# UDPデータをログに記録
thisExp.addData('UDP_Data', latest_udp_data)
thisExp.addData('KeyPress_Time', globalClock.getTime()) # キー押下時刻も記録
############# NAGANO #################
# a response ends the routine
continueRoutine = False
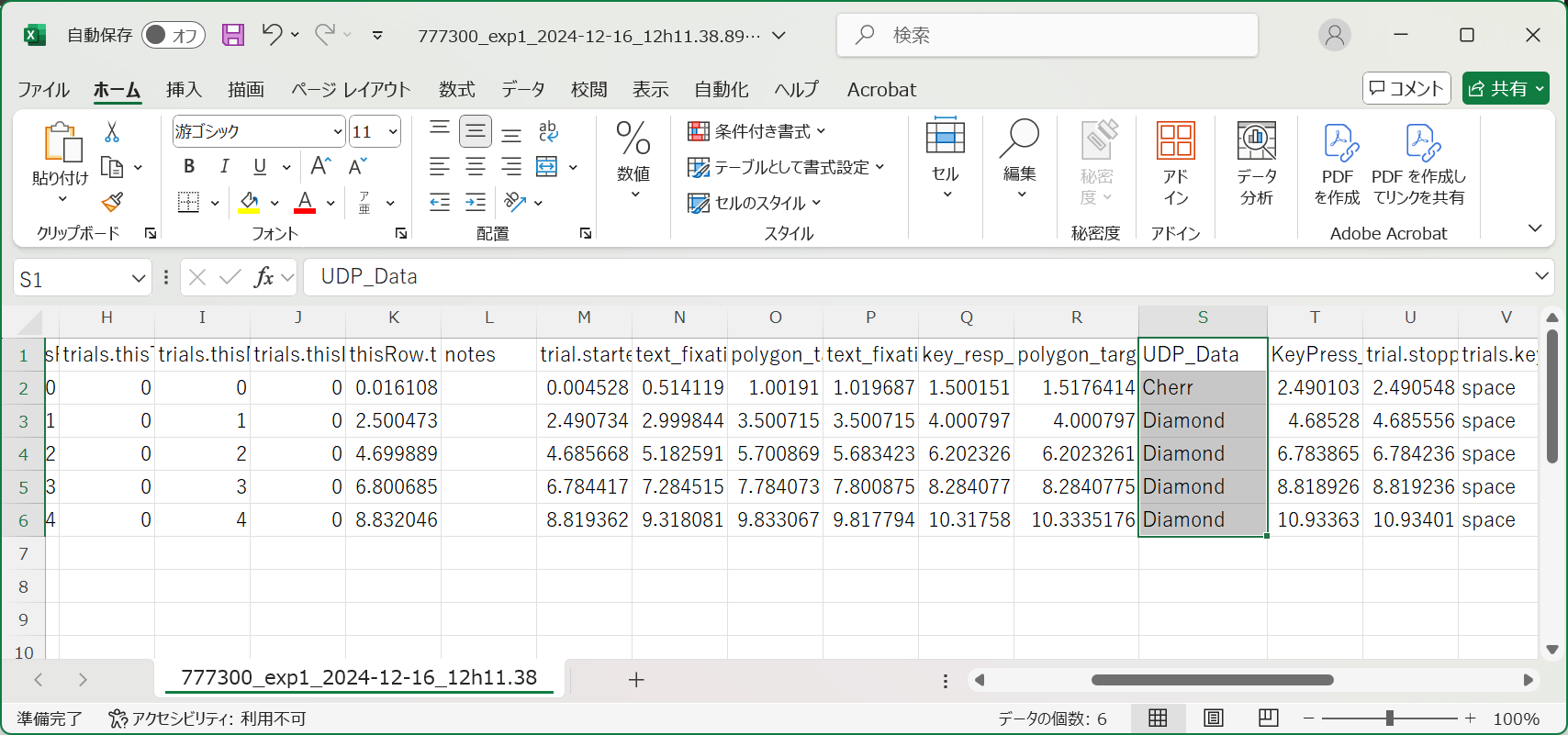
実行すると,以下のような感じでUDP経由で送られたデータが保存される。ちなみに,データ送信側は,ローカルホストの5005ポートにProcessingでCerry,Diamond,Sevenのどれかひとつの文字列を送るもの。もう一度いうが,Builderで更新するとこれらの改造部分は消し飛ぶので注意!
SpeakerID一覧
VoiceVOXやCoeiroInkのSpeakerIDが必要になるときがある。・・・あるんだってば。VoiceVOXに関してはここから参照。
| キャラクター名 | スタイル | ID |
|---|---|---|
| 四国めたん | ノーマル | 2 |
| あまあま | 0 | |
| ツンツン | 6 | |
| セクシー | 4 | |
| ささやき | 36 | |
| ヒソヒソ | 37 | |
| ずんだもん | ノーマル | 3 |
| あまあま | 1 | |
| ツンツン | 7 | |
| セクシー | 5 | |
| ささやき | 22 | |
| ヒソヒソ | 38 | |
| 春日部つむぎ | ノーマル | 8 |
| 雨晴はう | ノーマル | 10 |
| 波音リツ | ノーマル | 9 |
| 玄野武宏 | ノーマル | 11 |
| 喜び | 39 | |
| ツンギレ | 40 | |
| 悲しみ | 41 | |
| 白上虎太郎 | ふつう | 12 |
| わーい | 32 | |
| びくびく | 33 | |
| おこ | 34 | |
| びえーん | 35 | |
| 青山龍星 | ノーマル | 13 |
| 冥鳴ひまり | ノーマル | 14 |
| 九州そら | ノーマル | 16 |
| あまあま | 15 | |
| ツンツン | 18 | |
| セクシー | 17 | |
| ささやき | 19 | |
| もち子さん | ノーマル | 20 |
| 剣崎雌雄 | ノーマル | 21 |
| WhiteCUL | ノーマル | 23 |
| たのしい | 24 | |
| かなしい | 25 | |
| びえーん | 26 | |
| 後鬼 | 人間ver. | 27 |
| ぬいぐるみver. | 28 | |
| No.7 | ノーマル | 29 |
| アナウンス | 30 | |
| 読み聞かせ | 31 | |
| ちび式じい | ノーマル | 42 |
| 櫻歌ミコ | ノーマル | 43 |
| 第二形態 | 44 | |
| ロリ | 45 | |
| 小夜/SAYO | ノーマル | 46 |
| ナースロボ_タイプT | ノーマル | 47 |
| 楽々 | 48 | |
| 恐怖 | 49 | |
| 内緒話 | 50 |
CoeiroINKは下記のような感じ
//つくよみちゃん(れいせい) 0
//つくよみちゃん(おしとやか) 5
//つくよみちゃん(元気) 6
//KANA(のーまる) 30
//KANA(えんげき) 31
//KANA(ほうかご) 32
//リリンちゃん(ノーマル) 90
//リリンちゃん(ささやき) 91
//モモイヒナ-A 1737595468
//KAKU_N 259
//KAKU_W 260
AI教材2024-1
Python編
Anacondaをインストールし、環境をつくるところまでは一緒。新しいライブラリ(1.0.0以降)に対応したコードがなかなか見つからない。今回はここを参考にした。Pythonのバージョンは3.10.15、OPENAIライブラリのバージョンは1.57.0。
追加予定コンテンツ:GPT4Vによる画像解析、Voicevoxとの連携
GPT01/最低限のコード
文章作成を行うための最低限のコード。Temperatureが指定できる。
#GPT01.py
#GPT4を使って文章生成を行う最低限のコード
from openai import OpenAI
client = OpenAI(api_key="sk-hogehoge")
completion = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "あなたは大学図書館の優秀な受付です"},
{"role": "user", "content": "初めて図書館に来た大学生に、図書館の魅力を200文字で伝えてください。"}
],
#temperature=0.1文章が一貫性の高い回答
#temperature=0.9より創造的で予想外な回答
temperature=0.7
)
# 日本語の文字列部分だけを取得
response_text = completion.choices[0].message.content
print(response_text)
GPT02/使用したトークンの取得
文章生成に使用したトークンの数を表示してくれる
#GPT02.py
#GPT4を使って文章生成を行い消費したトークンを表示
from openai import OpenAI
client = OpenAI(api_key="sk-hogehoge")
completion = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "あなたは大学図書館の優秀な受付です"},
{"role": "user", "content": "初めて図書館に来た大学生に、図書館の魅力を200文字で伝えてください。"}
],
temperature=0.7
)
# 日本語の文字列部分だけを取得
response_text = completion.choices[0].message.content
print(response_text)
# 消費したトークン数を表示
total_tokens = completion.usage.total_tokens
prompt_tokens = completion.usage.prompt_tokens
completion_tokens = completion.usage.completion_tokens
print(f"消費したトークン数: 合計 {total_tokens}, プロンプト {prompt_tokens}, 応答 {completion_tokens}")
Chat01/チャット用スクリプト
人格を設定して会話を行うことができる。
#Chat01.py
#設定した人格に基づいて、チャットを行うスクリプト。
from openai import OpenAI
client = OpenAI(api_key="sk-hogehoge")
personality = "あなたは、埼玉県内の大学に通う男子大学2年生です。所属学科は心理学科です。一人称は「僕」、二人称は「きみ」を使います。明るく気さくな感じで話します。「〇〇だよな」「〇〇だな」「〇〇だろ?」「〇〇だと思う」などの語尾を使って話します。"
# 初期設定
messages = [
{"role": "system", "content": personality}
]
print("模擬人格と会話を始めます。'終了'と入力すると終了します。")
while True:
# ユーザーの入力を受け取る
user_input = input("user: ")
# 終了コマンド
if user_input.strip() == "終了":
print("会話を終了します。")
break
# ユーザー発言を保存
messages.append({"role": "user", "content": user_input})
# 会話履歴を最新20件に制限
if len(messages) > 21: # 21 = systemメッセージ + 過去20回の履歴
messages.pop(1) # 最初のユーザーかアシスタントの履歴を削除
# OpenAI APIにリクエスト
completion = client.chat.completions.create( # 修正箇所
model="gpt-4o",
messages=messages,
temperature=0.7
)
# アシスタントの応答を取得
assistant_response = completion.choices[0].message.content
print(f"assistant: {assistant_response}")
# アシスタントの応答を保存
messages.append({"role": "assistant", "content": assistant_response})
VVOX01/合成音声を作成する最低限のスクリプト
ローカルで実行中のvoicevoxにむかってテキストを送り込み、合成音声として再生してもらいます。voicevoxのspeakerIDはこちらを参照。
#VVOX01.py
#ローカルで起動したvoicevoxに、pythonから文字を送って合成音声を再生するスクリプト。
import requests
import json
from pydub import AudioSegment, playback
HOSTNAME='http://localhost:50021'
speaker = 3 #ずんだもん
msg="こんにちは、ずんだもんです!"
def playsound(text):
# audio_query (音声合成用のクエリを作成するAPI)
res1 = requests.post(HOSTNAME + '/audio_query',
params={'text': text, 'speaker': speaker})
# synthesis (音声合成するAPI)
res2 = requests.post(HOSTNAME + '/synthesis',
params={'speaker': speaker},
data=json.dumps(res1.json()))
# wavの音声を再生
playback.play(AudioSegment(res2.content,
sample_width=2, frame_rate=22050, channels=1))
playsound(msg)
Chat02/合成音声でAIとチャットを行うスクリプト
チャットスクリプトと合成音声スクリプトを統合したもの
#Chat02.py
#設定した人格に基づいて、チャットを行い、AIの返答を合成音声で返答するスクリプト。
from openai import OpenAI
import requests
import json
from pydub import AudioSegment, playback
# OpenAI API設定
client = OpenAI(api_key="sk-hogehoge")
# VoiceVox設定
HOSTNAME = 'http://localhost:50021'
speaker = 13 # 青山龍星
def playsound(text):
"""VoiceVoxで音声合成して再生する"""
# audio_query (音声合成用のクエリを作成するAPI)
res1 = requests.post(HOSTNAME + '/audio_query',
params={'text': text, 'speaker': speaker})
# synthesis (音声合成するAPI)
res2 = requests.post(HOSTNAME + '/synthesis',
params={'speaker': speaker},
data=json.dumps(res1.json()))
# wavの音声を再生
playback.play(AudioSegment(res2.content,
sample_width=2, frame_rate=24000, channels=1))
# AIの人格設定
personality = "あなたは、アイオワ州在住の陸軍兵士です。一人称は「おれ」、二人称は「おまえ」を使います。「〇〇だよな」「〇〇だな」「〇〇だろ?」「〇〇だと思う」などの語尾を使って話します。ぶっきらぼうだけど、本当は優しい性格で、ユーザーの会話を掘り下げ、悩み相談にのってくれる。"
# 初期設定
messages = [
{"role": "system", "content": personality}
]
print("模擬人格と会話を始めます。'終了'と入力すると終了します。")
while True:
# ユーザーの入力を受け取る
user_input = input("user: ")
# 終了コマンド
if user_input.strip() == "終了":
print("会話を終了します。")
break
# ユーザー発言を保存
messages.append({"role": "user", "content": user_input})
# 会話履歴を最新20件に制限
if len(messages) > 21:
messages.pop(1)
# OpenAI APIにリクエスト
completion = client.chat.completions.create(
model="gpt-4o",
messages=messages,
temperature=0.7
)
# アシスタントの応答を取得
assistant_response = completion.choices[0].message.content
print(f"assistant: {assistant_response}")
# アシスタントの応答を保存
messages.append({"role": "assistant", "content": assistant_response})
# VoiceVoxで音声合成&再生
playsound(assistant_response)
GPT4V/画像を読み込み解釈する
指定したファイル名の画像を、プロンプトに従って解釈し、説明します。
#GPT4V.py
#画像を読み込んで、説明を行うスクリプト。
import base64
from pathlib import Path
from openai import OpenAI
client = OpenAI(api_key="sk-hogehoge")
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
image_path = "picture1.jpg"
base64_image = encode_image(image_path)
file_extension = Path(image_path).suffix
file_extension_without_dot = file_extension[1:]
url = f"data:image/{file_extension_without_dot};base64,{base64_image}"
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "どのような状況か300文字くらいで説明してください。季節も推測してください。",
},
{
"type": "image_url",
"image_url": {
"url": url,
},
},
],
}
],
max_tokens=1000,
)
print(response.choices[0].message.content)
OpenCV/Face241124
FacialExpressionRecognitionAI
UnityのOpenCVで表情判定を行い、その結果をさらにUDPでProcessingに送る。詳しくは動画に。
HealingMusic
Regardless of Outcome. Cosmic Evolutionなど
Solar SonarのSoaring
Sur Sagano How to Heal
MikuLiveUnity#01
MMD その1
MMDとは「MikuMikuDance」の略称で樋口優氏によるフリーの軽快な3DPV作成ツールである(pixiv百科事典)。
元々は初音ミクを踊らせる3Dアニメーション制作ツールであり、現在ではその他キャラクターにも幅広く対応し、自作PVやキャラクターのダンス動画などがニコニコ、YouTubeに多数投稿されている。
・・・というか、キャラクター以外のアセットやモデルも多数存在し、その汎用性は幅広い。
現長野ゼミでは主にunityを用いてアニメーションや3D空間の作成を行っているが、キャラクターを踊らせる程度であれば、このソフトウェアも使えるかもしれない。
ということで、MMDの導入から簡単な3Dアニメーションの作成までの雑感をまとめておこうと思う(建前)。
以下導入に当たり、以下のサイトや動画を参考に進めていく。詳細はこちらを参照されたし。
MMDの導入を紹介している動画:
https://youtube.com/playlist?list=PL7Jbc_YxpkriO7nb-QzvDFwozgc1O3s0F&feature=shared
同作者による導入ブログ(他にもAIやDTMなど多数紹介):
https://how-to-use-music-video.com/
自作でモーションを作る方法の説明をしているブログ
https://note.com/tareire/n/n22d17c2a4c4b
初心者向けの解説動画
https://www.youtube.com/watch?v=Jp7wf4TNcA0
同じように初心者向けの動画
https://www.youtube.com/watch?v=G2vLiDWKMgY
また、使用したPCのスペックは以下の通り
プロセッサ Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz 2.59 GHz
実装 RAM 16.0 GB (15.8 GB 使用可能)
システムの種類 64 ビット オペレーティング システム、x64 ベース プロセッサ
GPU NVIDIA GeForce MX250
MMDの導入
前置きが長くなりましたが、本題に入ります
まず、
https://sites.google.com/view/vpvp/
のサイトにアクセスし64bit版Windows用をダウンロード(ZIPファイルでDLすることになる)する。
note:ほかに32bit版も存在する。この辺りは自分のPCスペックを参照のこと。
ZIPファイルを適当な場所に展開しその中にある「MikuMikuDance.exe」をクリックし、起動する。
note:その下にあるreadme.txtに開発者からの説明やバージョン情報などが書きこまれている
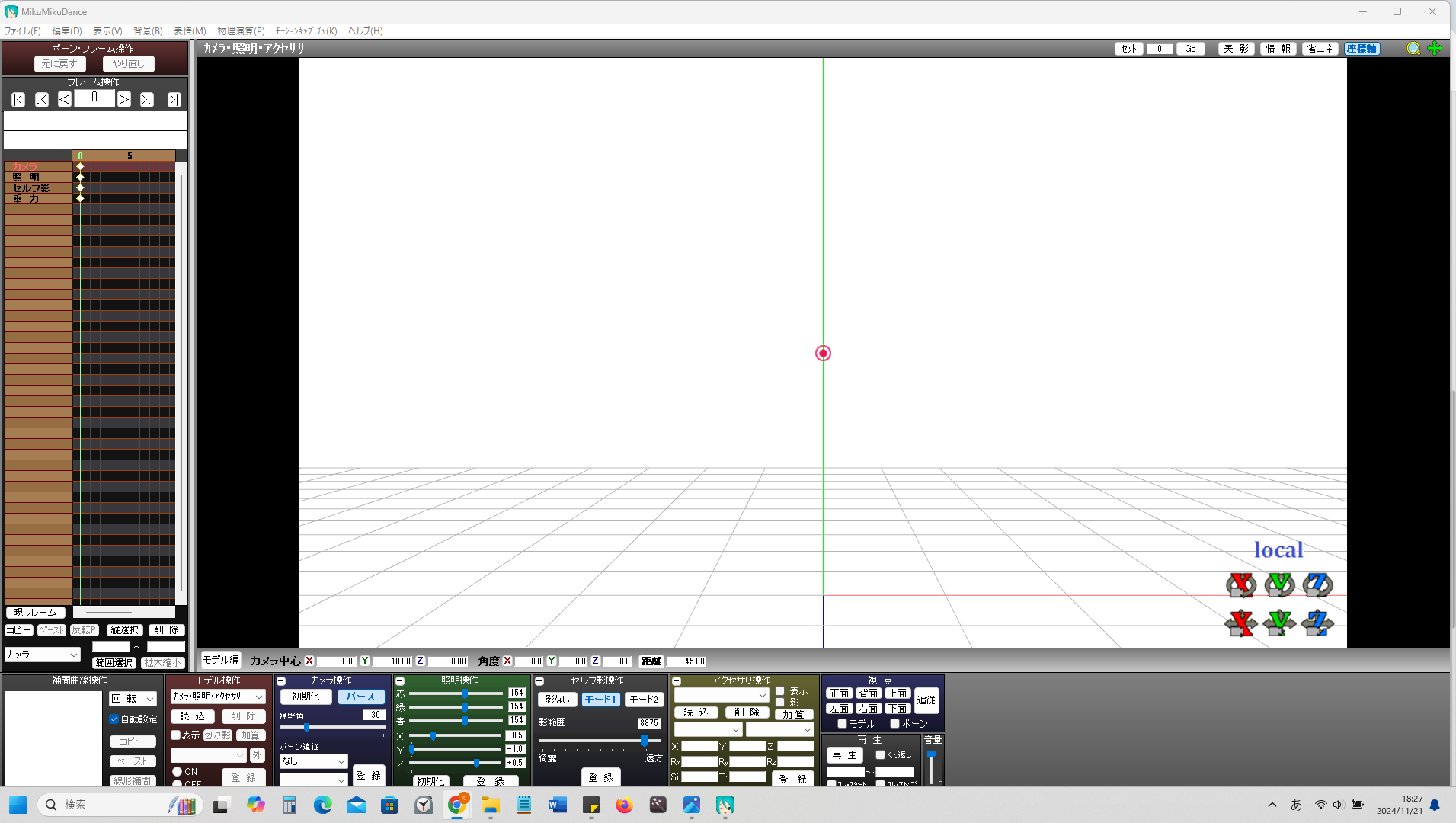
時折見る編集画面が出てきた。
導入自体はこれで完了。感想としてはひたすらに軽い。
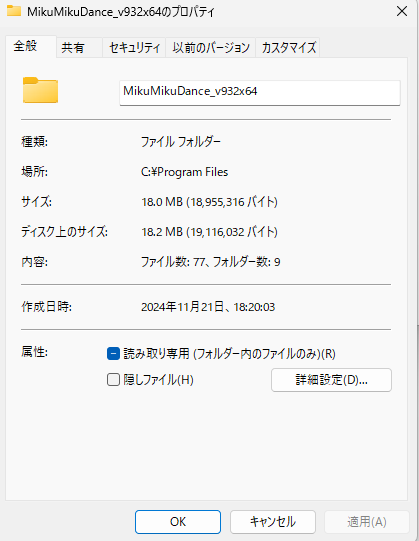
プロパティを開くと18.2MBくらいしかない。
unityと比べるとだいぶ軽いなぁ・・・
今回はこの辺りで。
23mh203 修士論文
電極クリップ3Dファイル
PVセンサーアタッチメント

笑顔でShoot!240920
Unity用のDlibライブラリ,結構速かったように思う。フルバージョンでなく17ポイントバージョンなどを使えば高速化が期待できる。最新版に更新して試してみると,「sp_human_face_68_for_mobile」などのモバイル版モデルが入っていた(前から?)。ということは,WebGLでも高速な笑顔検出ができるのでは??試してみると普通に30FPS(おそらく内部的にはもっと?)出てる。ARHeadでは,頭部の姿勢推定も可能となっているはず。。。こちらもEnableDownscaleで30FPS出るようになった。笑顔推定をDlibで行えばAffectiveGamesも実運用可能と思われる。
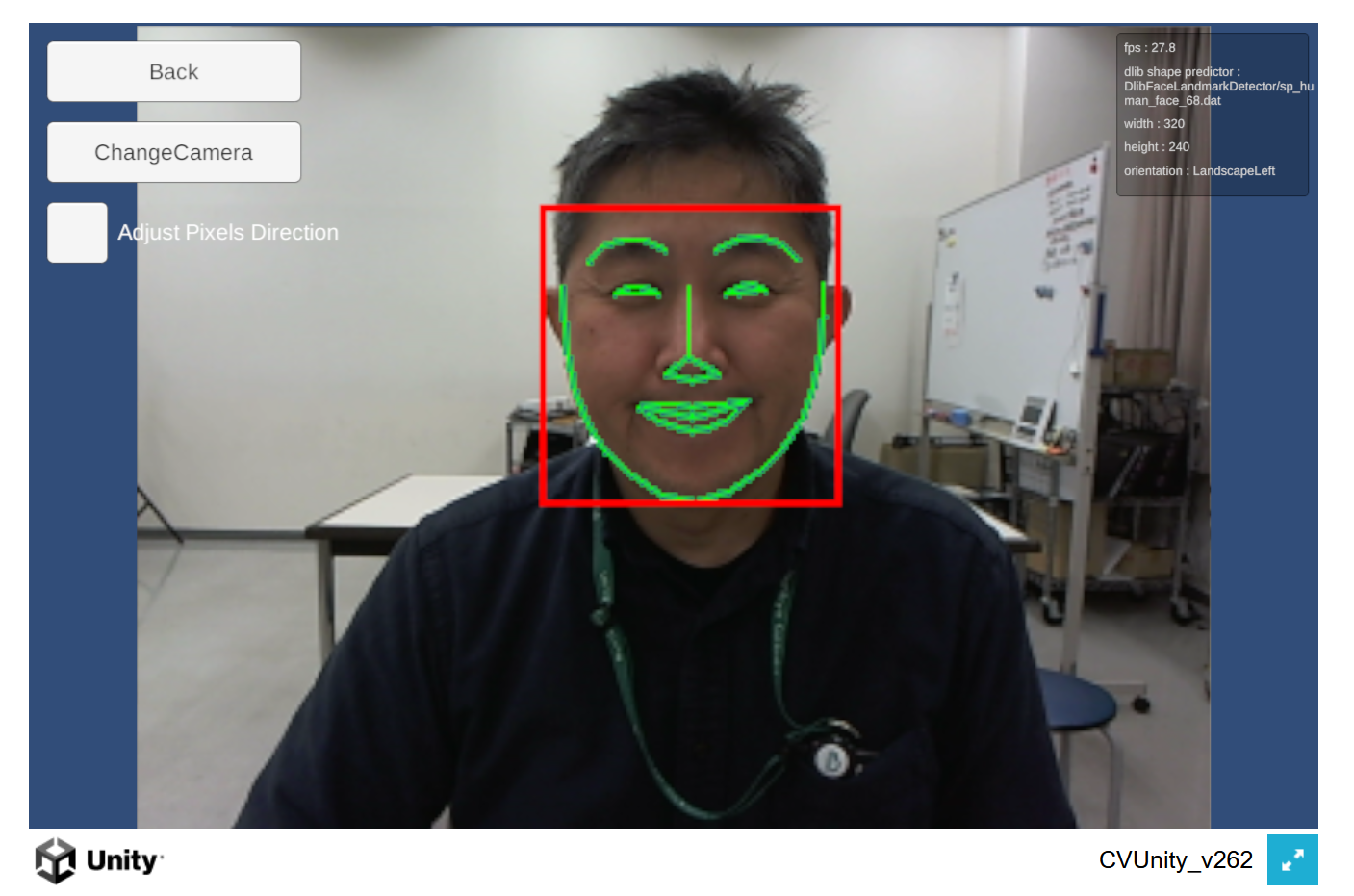

あらためて冷静に見ると,WebCamで画面との距離や頭の姿勢,表情判定に使用可能な68特徴点を連続的に取得できるのは,かなりお得じゃないか?しかもWebGLでって。お手軽データ測定にこれを導入してみるのも良いかもしんない。
笑顔でShoot!
導入
いただきました,その名前。今日,諸先生がたと立ち話した収穫として,「クソゲー連発案は有用であること」,「感情把握アプリは老人業界にも有用」などのこと。FaceAnalyzerはよく見るとWebGL未対応のようで,そうなるとOpenGLでやるしかない。WebGLだとブラウザ立ち上げるだけで,AffectiveComputing技術ベースのアプリが利用できる可能性がある。
善は急げでビルドしてみる・・・
OpenCV4Unityはサポートバージョンが上がっていたので,いっそUnity6にしてみるが・・・ビルドできず(泣)。マニュアルを読むと,バージョンによってWebGLのプラグインが異なるらしいので,2023.2.20にしてみる。ビルドは通るが公式DEMOより明らかに遅い!何故だ!!MultiThredとSIMDを有効にしてみる・・・「ブラウザはマルチスレッドをサポートしてません(FirefoxもChromeも)」で起動すらせず。SIMDのみにしてみる。無事に動作した! これで表情利用したWebGLアプリをリリースできそうだ。・・・動作が13fpsなのが気になる。解像度を320x240にすると22FPSに。もう少し速くなるといいんだけどなぁ。科学技術のげ限界っ!

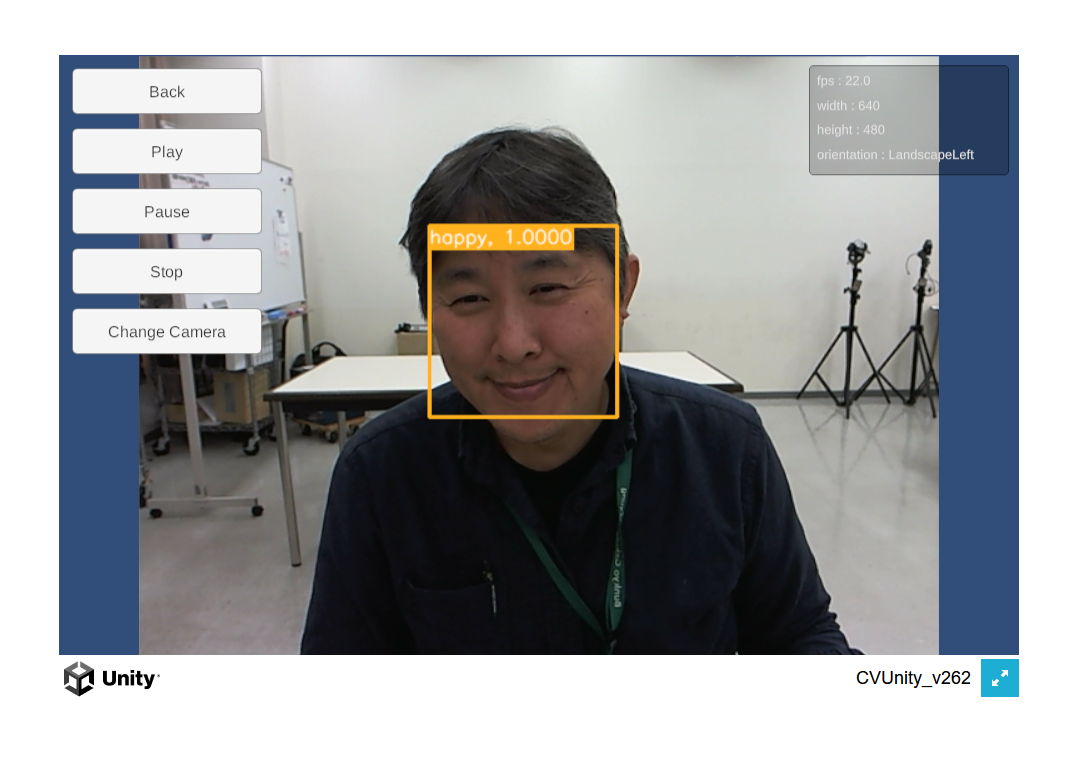

遅い・・・
どうも純粋にCPUを使っており、かつシングルスレッドのためか、かなり遅い。Corei5_9600kで6.7FPSは衝撃の遅さだ(Ryzen7_6800Uの方が速い)。AIアプリの実行環境はPCネイティブ環境しかダメということか・・・。いっそAndroidに行くというのは?手持ちで一番速そうなHelioG99にAndroidネイティブアプリを入れてみると、19~22FPS程度。WebGLよりは速いけど、ちょっと・・・なぁ。



マルチスレッド対応の効果見られず
WebGLはUnity2022あたりからマルチスレッドに対応しているという。そこでマルチスレッド対応バージョンをビルドしてみた。ブラウザが「マルチスレッドに対応していません」と言う場合は,下記のヘッダを.htaccessで設置すれば動くようになる。アプリがロード中に止まるのはメモリ不足なので,使用可能メモリを倍にすればロードするようになる。結果として,フレームレート変わらねぇ・・(怒)。プログラムがマルチスレッド対応してないと意味ないということか?
<IfModule mod_headers.c>
Header set Cross-Origin-Opener-Policy "same-origin"
Header set Cross-Origin-Embedder-Policy "require-corp"
</IfModule>
UnityXWhisper240913
導入
自動車の中でAIと会話する未来は「ほぼ確定」だと思う。いろいろ便利だし,気晴らしになるし,運転中一人で寂しいし・・・。OS標準の音声認識はいろいろボタンを押さなければならず,運転中の操作には問題がある。googleSTT(SpeechToText)やWhisperを使えば,ハンズフリーで会話ができるはずだ(OpenAIアプリのように)。PCアプリであっても,キー操作が必要なくなればより没入感というか,人と話してる感が高まるのではないか?
Whisper対応を強化
すでにUnityから利用可能なように知見を貯めていたが,ハンズフリーを目指して大幅介入だ。以前のバージョンはRecordを押して喋りStopを押すと変換されたが,これは2度もボタンを押さねばならん(しかも違うボタン)。次はRecordを押すと録音が始まり離すと変換される形式。最終的には音圧をチェックし,しきい値を超えたら録音開始,下回ったら停止して変換。これなら連続して変換が可能だ。画像じゃわからないので,動作の様子を録画しようと思う。明日にでも・・・。
googleSpeechToText
googleのSpeechToTextAPIをアセットから使う方法。APIの作成がちょっとめんどくさいので残しておく。
【Unity】自分の声をテキスト化する方法【Google Cloud Speech Recognition 】
AIzaSyDq1sCszZ4oVelnKgRUuBznmKLwbecvIus
WebGLTemplates
いきさつ
webglのビルドをする時,ブラウザ上で実行されるアプリの見た目をカスタマイズしたい場合がある。WebGLTemplatesはそのための機能だ。今回はspeechblendでリップシンクを行う必要が出てきたため,ビルド後のindex.htmlにいろいろ追加する必要がある。そこで,WebGLTemplatesの使い方を調べてみた。
UnityのWebGL templatesについて調べてみた
WebGL テンプレート
やりかた
アセットフォルダにWebGLTemplatesというフォルダを作成し,そこにGL6などのテンプレート用のフォルダを作成する。中身は, エディターに入っている標準のテンプレート(C:\Program Files\Unity\Hub\Editor\yyyy.x.z\Editor\Data\PlaybackEngines\WebGLSupport\BuildTools\WebGLTemplates深いよ!)を改造するのが良いらしい。すると,Player設定のTemplatesに表示される。webglアプリの左下に表示されるUnityのロゴを,独自の模擬人格ロゴに変えてみた。もちろんindex.htmlもspeechblendに対応しているので,今後はビルドするだけで良い。
Windows ServerでDjango使ってWebアプリ作る
なんの共有もしない記事です。「小生、Win Server 使ってDjangoでWebアプリ作れるようになったデュフゥーw 」っていう自慢話です。正直二度とやりたくない。
事の発端
前にWebアプリケーションのベースを作ったんですが、自分が契約してるWin Serverに移管することにしました。途中までPHPでバックエンドのアプリケーションを作っていましたが、今後PHPを使う予定がないのと、VPSでWebアプリを動かしてみたかったという理由からVPSに移管します。
やったこと
- 外部に公開するポートの設定(FTP通信の設定と同じ)
- Windows ServerのIIS設定
- Djangoでプロジェクト立ち上げ
この3つです。
ネットワーク関係は大体ネットに書いてある記事をそのままやってもファイヤーウォールに邪魔されて「動かねーじゃねぇか。このxxxxxx(怒怒怒怒怒怒怒)」と台パンすることになります。
長野研ではFlask使ってるようなので、Djangoは使わないと思うのでいろいろ説明は省略しますが、添付のpdfファイル(Djangoのアプリケーション作成手順書)とWin Server側でWebを行為買いできるようIISを設定したうえでこの記事の通りにやればローカル上では動きます。
ローカル上では動いているのでシステム的には問題がないんですが、外部からアクセスしようとするとブラウザに「ページが存在しない」といわれます。ここで1台パン。
記事後半に書いてある”python manage.py runserver <Server IPアドレス>:8000”でコマンド実行すれば、問題ないようなことを書いてあるが、これも失敗。ここで2台パン。
「末尾についてる8000というのはポート番号なので、Win Server側でポートを公開する設定がされていないのでは」とひらめきます。Win ServerにFTPでファイル送る設定したさいに60000ポート以降を開放していたの思い出したので60000番を設定して起動したところなんとデバッグ用のページにアクセスできたってわけですよ。いいね。
近況
残業多すぎて何のやるきも出ねぇっす。
Leonardoで,AI模擬人格との会話用コントローラーを作成(4)
BNO055を使用したコントローラーの開発経緯
AIagentは,いまやオープンキャンパスなど,色んなとこで引っ張りだこ。前回も本郷OCで高校生たちが興味津々に体験していたが,音声入力キー(Windows+H)など普段使い慣れておらず操作しにくいように見えた。そこで, 9軸センサーBNO055を使用して,キーボードレスの会話用コントローラーを作成しようと思う。使用方法と注意点は,下記の動画に示した。
1. 動画内で使用したプログラム
・BNO055_AIagent:今回使用したArduinoプログラム
・BNO055_tes2:小ネタでしたクォータニオン角でのカーソル操作(上下が弱い)
・BNO055_AgentControleer:カーソル操作+ボタン機能を統合した完成系
・WebcamGPT4V_New.txt:改造後のWebcamGPT4Vのスクリプト
・Changecam.txt:改造前のWebcamGPT4Vのスクリプト
2. ボタンの各機能_240912にカーソル操作を追加
①原点:Unityの基本操作
| ボタン | 機能 |
| ボタン1 | ゲーム実行/停止(Ctrl+P) |
| ボタン2 | カメラの視点交換(F5) |
| (ボタン2)×2回 | ボタン2を2回押すとダブルクリック |
| ボタン3 | 撮影ボタン(F4) |
②Y軸(横の傾き)±75°以上:入力の修正ボタン
| ボタン1 | カーソルキー「←」 |
| ボタン2 | カーソルキー「→」 |
| ボタン3 | Backspace |
③Z軸(前後に倒す)±30°以上:会話ボタン
| ボタン1 | キャラクタのチェンジ(F6) |
| ボタン2 | 音声入力(Windows+H) |
| ボタン3 | 送信(Enter) |
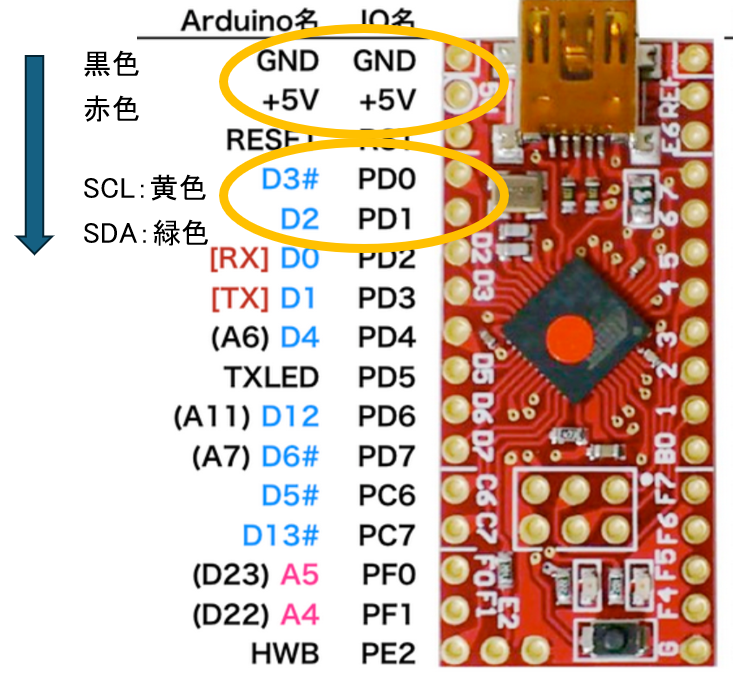
3. ピンの接続位置_BNO055
・VIN:5V
・GND:GND
・SDA:D2(PD1)
・SCL:D3(PD0)
黒→赤→黄→緑色の順で,はんだ付けする。

======================================================================
↓240904に,2台目を作成した。

convaiでNPC
CharacterCreatorを購入しようかと思い,Youtubeのチュートリアルを調べていると,なんかconvaiというものが出てくる。なんだろう・・・と思っていると,これはゲームエンジンに「リアルな会話ができるNPCをお気楽に導入しよう」というフレームワークらしい。NvidiaがめちゃリアルなSFゲーム会話場面をデモしていたが,ああいうキャラが簡単に作れるというのだ。ホントにぃ・・・?
設定の手順はおおむね以下のマニュアルの通りである。マジで簡単だ。IDができれば,性格やバックストーリーや声など,クラウド上で設定した通りに動いてくれるというわけだ。
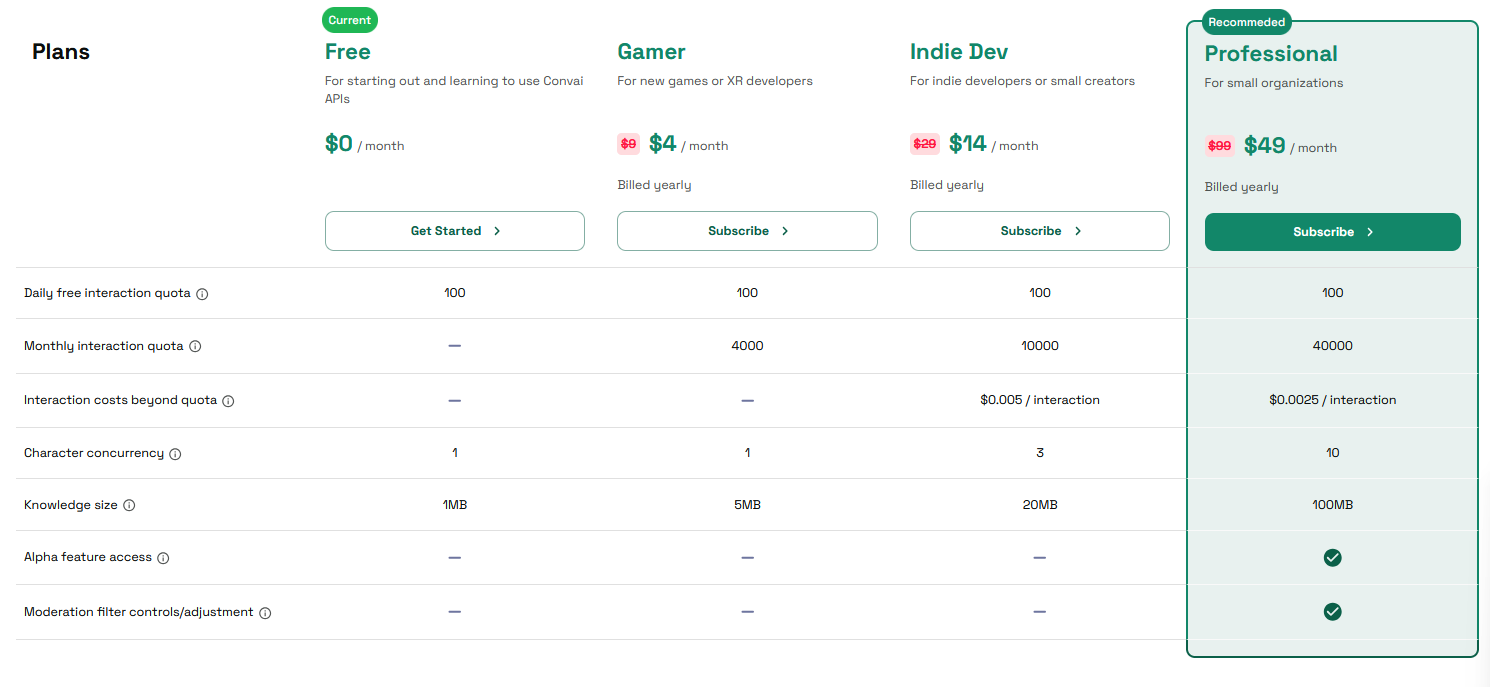
これ・・・料金体系がわからん。と思っていたら,無料で使えるのは1日100会話までであるらしい。恒常的に使いたかったら契約しろ・・・と。そりゃそうだよね。まぁNPC作りたければ使うかもしれぬ。会話の内容はほとんど完璧に思う。日本語の声の選択肢が多くないのが少し残念。これはこれですごいとは思うが,まぁNPCを作りたいわけではないので,あんまり気にしなくても良いと思われる。
本郷OCに持ってくもの
8/17(土), 18(日)に実施される本郷のオープンキャンパスに備え,持っていくものの一覧表をここにメモする。主に計測器やデジタルファブリケーション機器など。
展示するもの
1. デジファブ機器:3Dプリンタ,ミリングマシン,作成物の展示(BF装置など)
2. ジェンガ中の生体計測体験:ジェンガ中のSC・HRを計測する
3. AIエージェント:男性・女性キャラを展示して,AIとの会話体験
(4. 非接触の表情計測:AIによる非接触計測を紹介し,時間があれば体験も)
持っていくもの
1. デジファブ機器
①切削マシーン
・切削マシーン
・両面テープ
・生基板
・六角レンチ
・掃除機
・マジックペン
・スクレーパー
・予備のドリル×3本
・Dell PC,PC充電器
・科研費で作成したM5の完成物
②3Dプリンタ
・3Dプリンタ(Anker)
・TPUフィラメント:透明,オレンジ,緑色など
・工具:ニッパー,ペンチなど
・過去の作成物:BF装置,M5,フィギュアなど
2. ジェンガ中の計測体験
・ジェンガ→金井さんが購入
・計測器:SC計測器×6台(予備含む)
・電極:箱ごと→1日50人来ることもある
・計測器の充電器×2
・手袋×6(予備含む)
3. AIエージェント
・PC:MSI01, 02の2台
・PCの充電器×2
・Webカメラ×2:1台はタクトスイッチがついてるカメラ
(4. 表情の非接触計測→PCとカメラはAIエージェントと同じ)
・タブレット:実験室の水色のタブレット×2
・タブレット置き:木材で作成したタブレット置き
================================================================
向こうで展示した資料を下記に添付いたします。映像資料やその他ブース説明の詳細などは,Playgroundのこちらのブログに載せました。