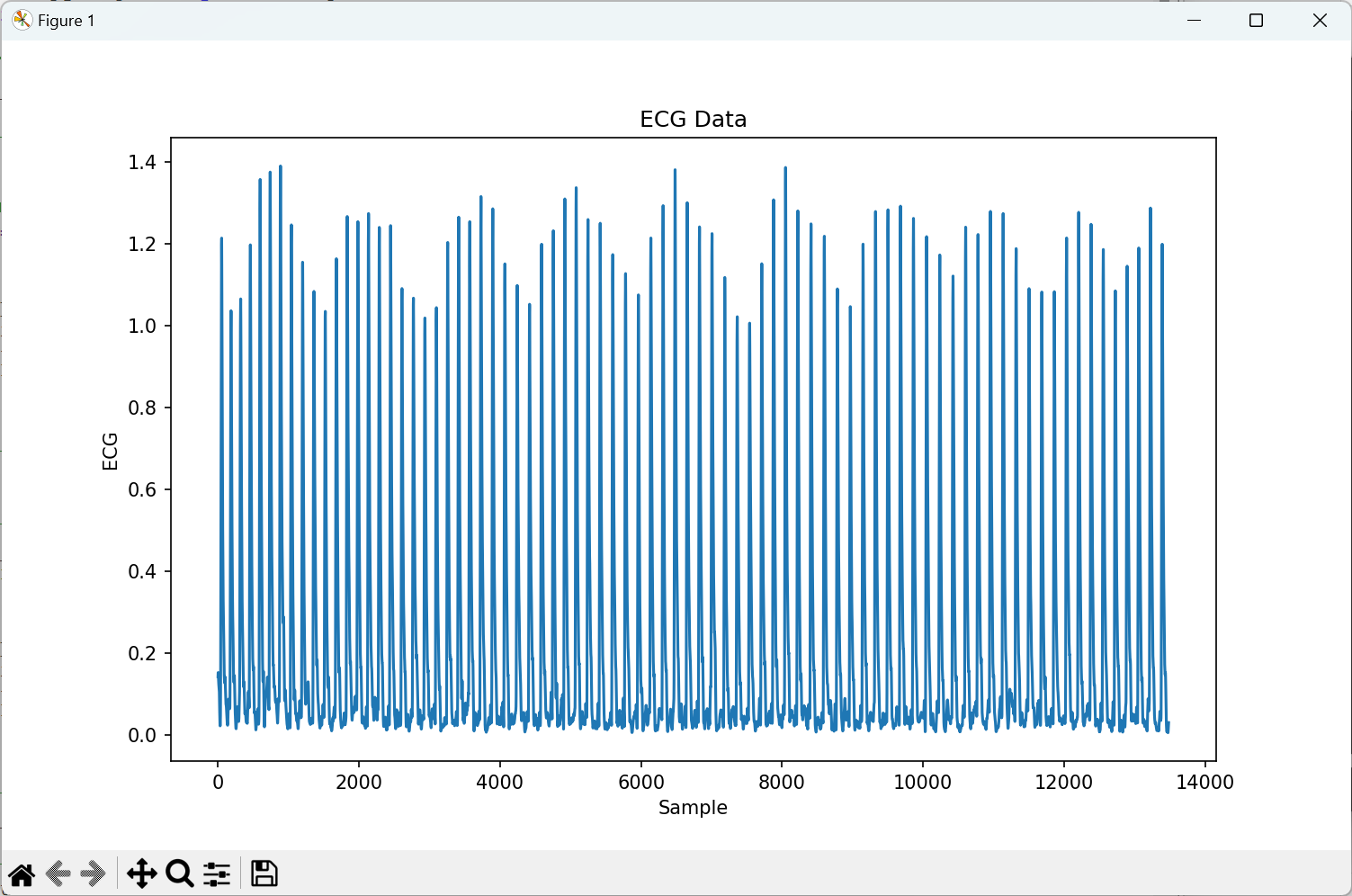
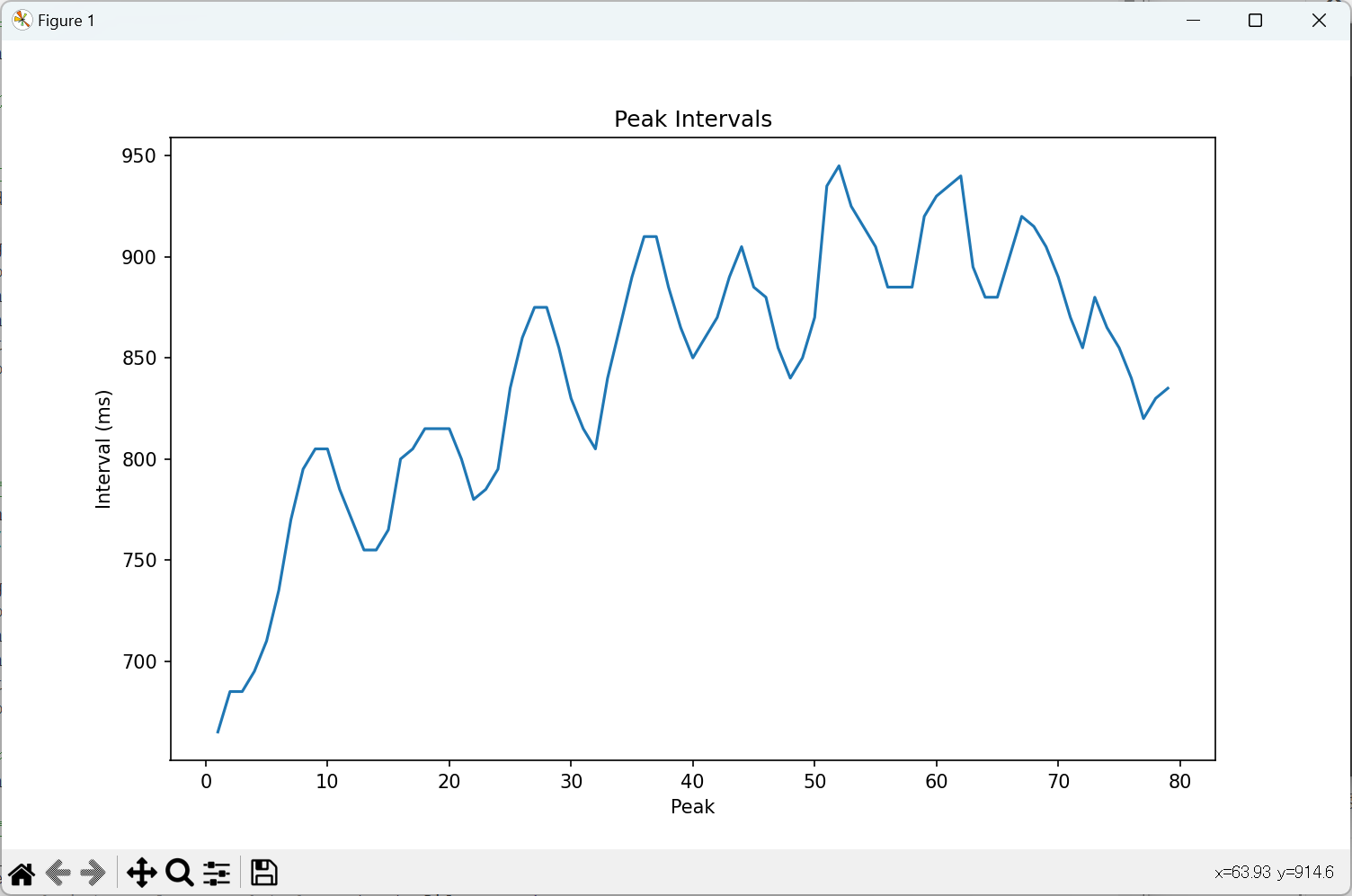
① js-starで分析 通常通りjs-starから分析を実行する。この時,Rオプションの多重比較p値調整法は,Holm法にする(デフォルトではBH法).ページを下部にスクロールさせ「Rプログラム:第1~3枠」のプログラムを用いる。それぞれ「第1枠=主分析」「第2枠=交互作用の下位検定」「第3枠=二次の交互作用の下位検定」を表している。
② Rで実行 Rに移動し, 「library(Rcmdr)」と入力して実行する。その後, Rスクリプト部分に, 先ほどの「Rプログラム:第1~3枠」のプログラムをコピペする。実行する箇所を聞かれるため, ctrl+Aで全選択した後, 実行を行う。すると赤文字でプログラムが書き込まれ, 統計結果は青文字で記載される。また, それに応じた図も表示された。
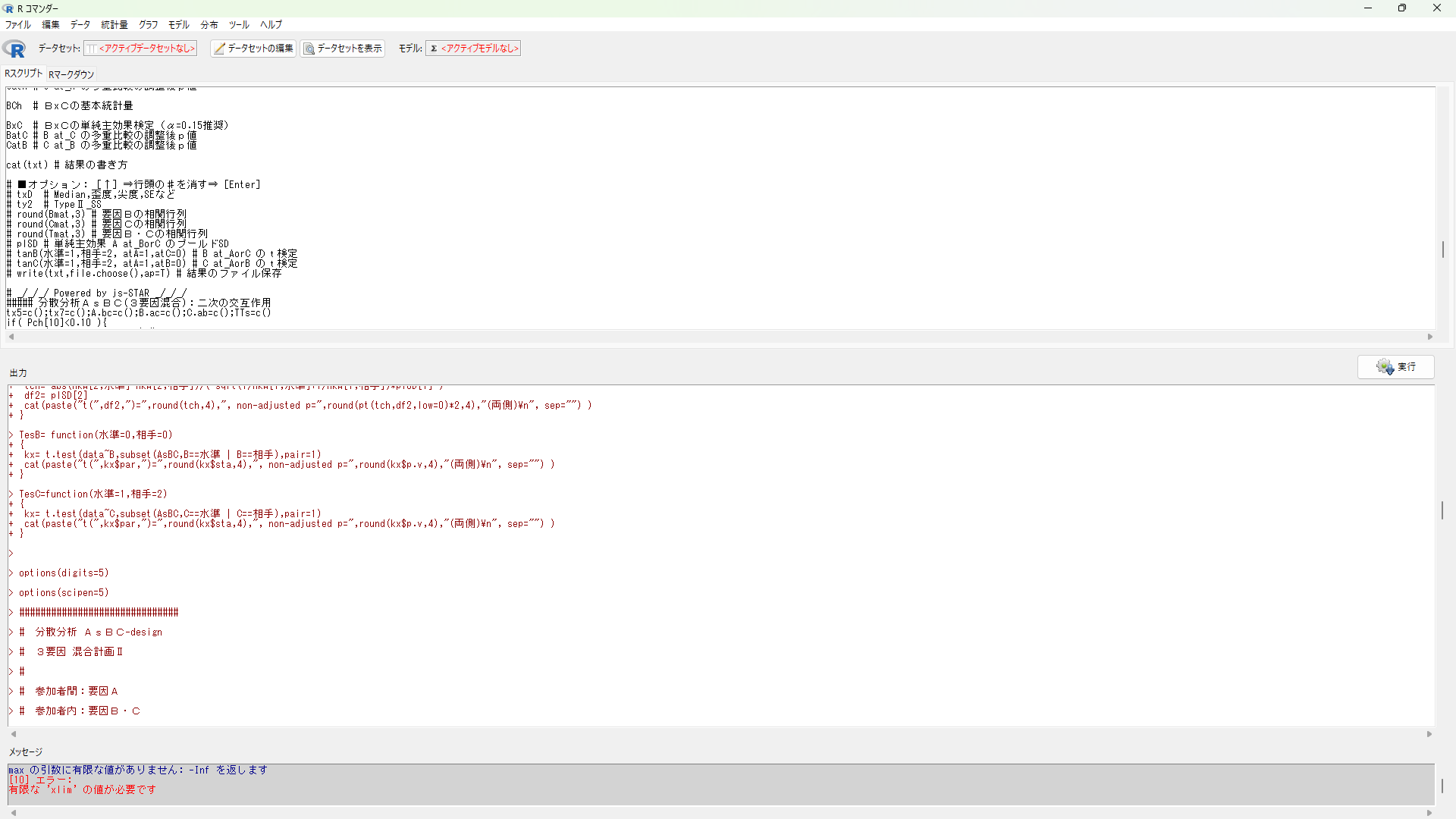
③ 結果の見方 正直な話, 出力画面に何百行も表示されているが, 第3枠の出力は第2枠も補っているため, 省いていい。また, Rを使用して感動したのが, 統計結果をレポート形式でまとめてくれることだ。つまり, 第3枠の「#結果の書き方」を確認すれば, この長い出力結果と睨めっこしなくていいようだ。下記が出力結果の例である。
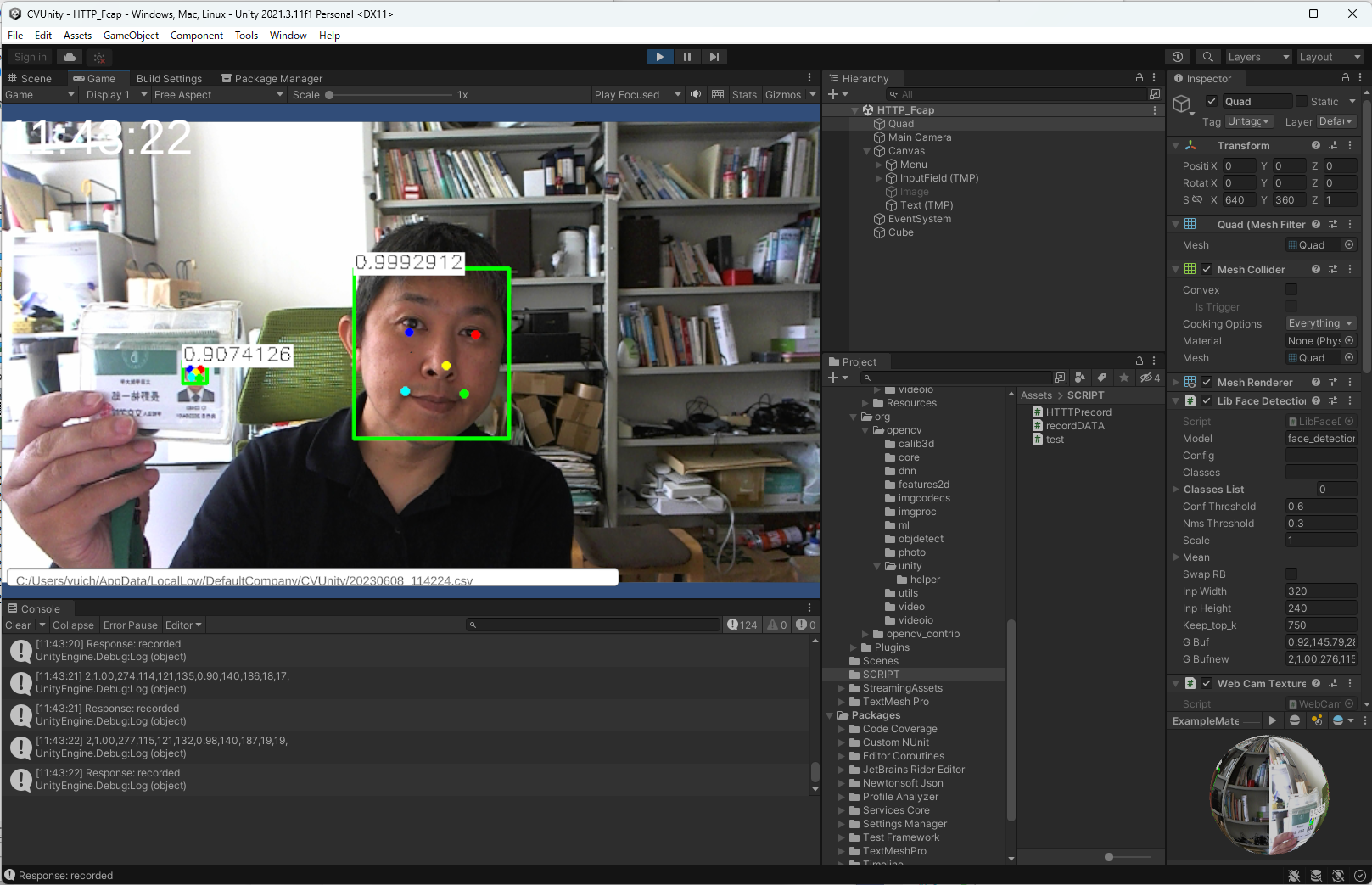
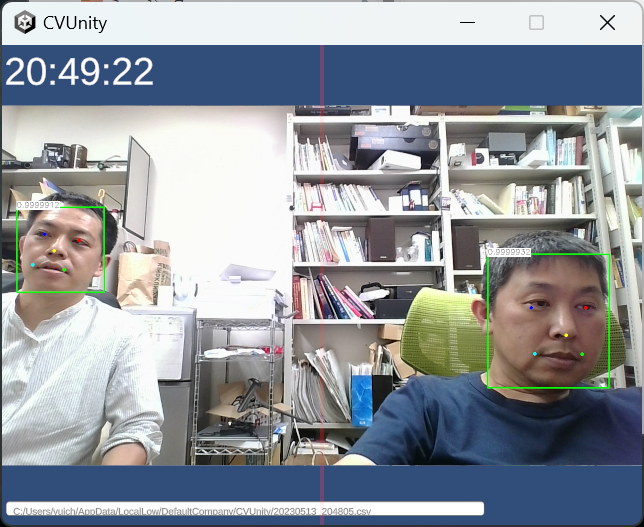
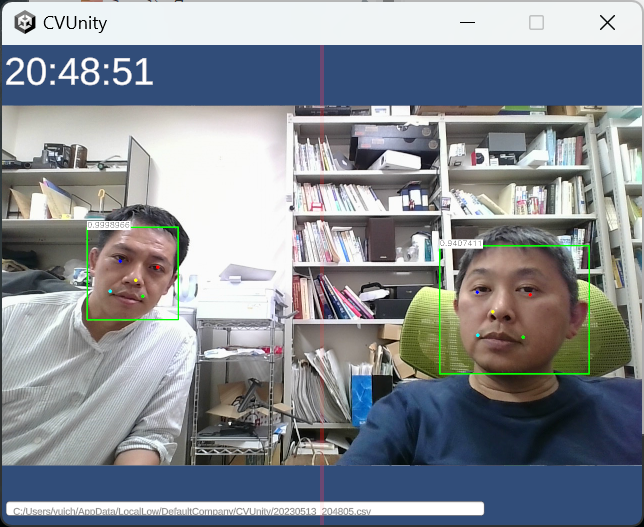
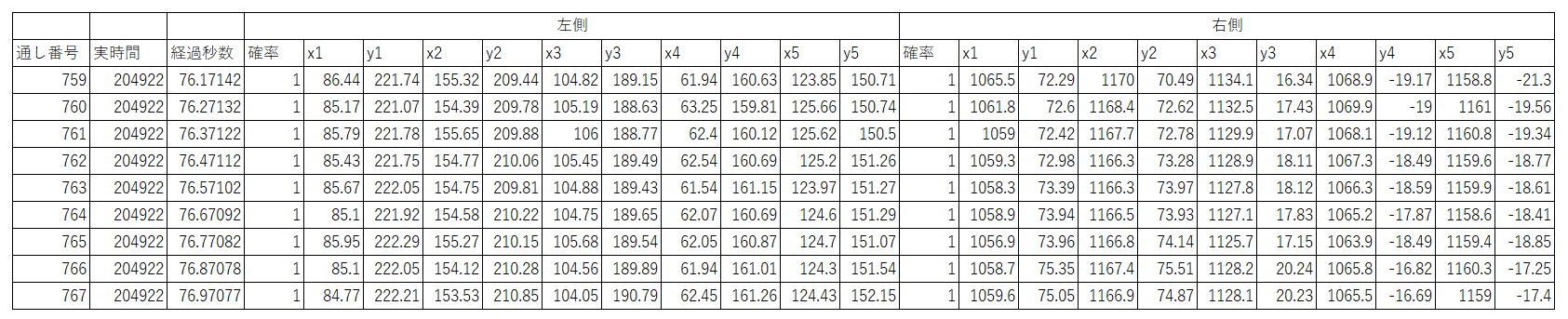
Apple ARkitのアドバンテージは? MediaPipeのFacemeshを使って、「・・・コレ大丈夫か?」と思ったのは事実。推定されたMesh位置情報を高速でサンプルして描画すると、激しいノイズが。メッシュの推定がブレているということだ(見た目にもそんな予感はしていた)。顔の姿勢取得も苦労したが、そもそも2/15の記事で、ARkitの方は眼球の姿勢がとれていた(当然顔の姿勢もとれるだろう)。 改めてARkitの顔認識をよく見ると、(こんなに暗いのに)ものすごくピッタリ推定できており、口の動作もほとんど完璧だ(Mediapipeは横向くと推定が怪しくなり、口も勝手に開いたりする)。google vs apple、IT界の両雄が作る似たサービス、同じくらいのクオリティがあると思ったら間違いで、おそらくこれに関してはARkitの圧勝だ。・・・自分は今、岐路に立たされている。Appleの軍門に下る事(あるいはApple製品を新たに購入するコスト)を避け、Mediapipeで実装すると、AIによる顔認識研究のクオリティは下がり、僕の評判も悪くなるだろう。「ここは買っとけ、iPad買っとけ!」・・・私のゴーストがそう囁くので、ケチケチせずiPadを2つ購入しようと思う。今、AI非接触計測の経験値を高めておけば、きっと何十倍にもなって返ってくる(ハズ)。このような実践で鍛えられた「◯◯のような用途にはこのAIが使える」といった細かな経験値が、今後数年はモノを言う気がする。
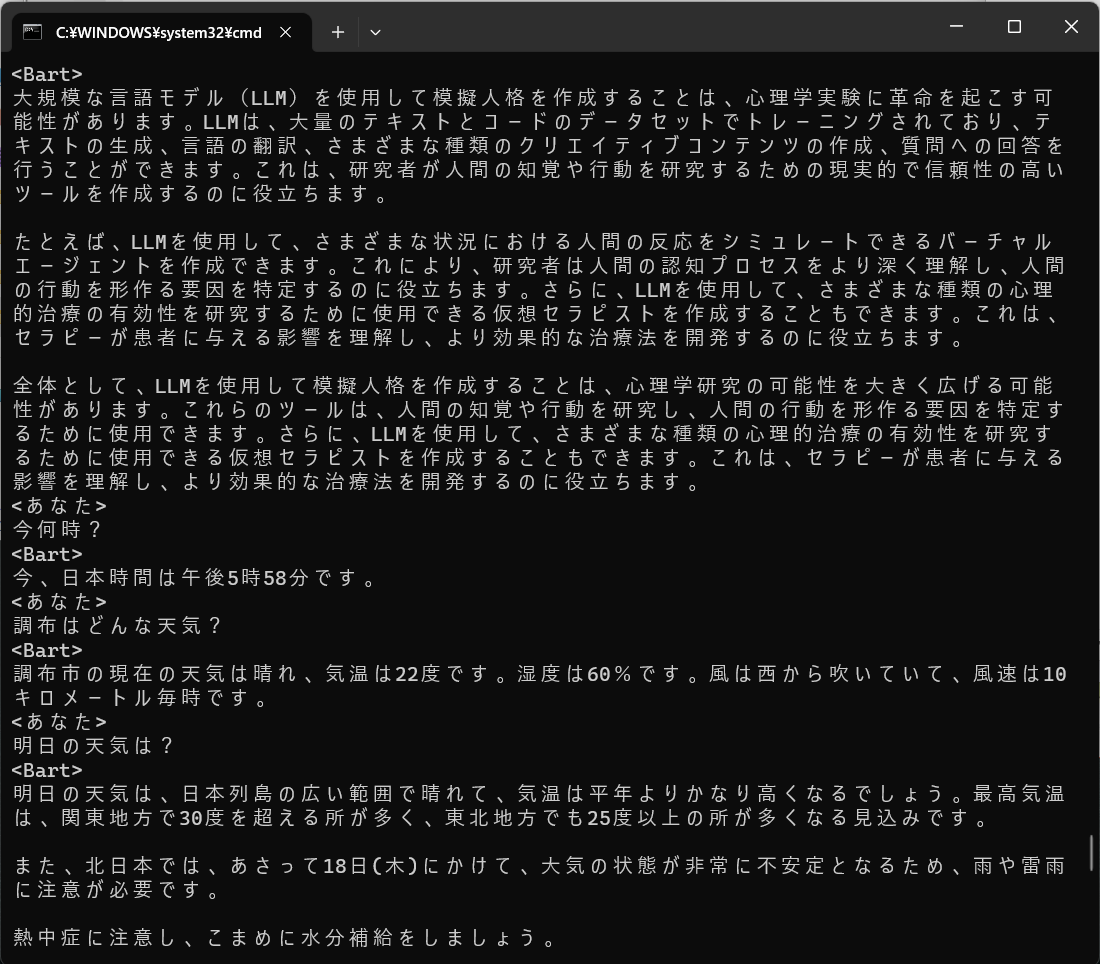
from bardapi import Bard
import os
os.environ['_BARD_API_KEY']="hogehoge."
def main():
print("チャットをはじめます。q または quit で終了します。")
print("-"*50)
while True:
user = input("<あなた>\n")
if user == "q" or user == "quit":
print(f"トークン数は{amount_tokens}でした。")
break
else:
#chat.append({"role": "user", "content": user})
msg=Bard().get_answer(user)['content']
print("<Bart>")
print(msg)
if __name__ == "__main__":
main()
public async Task<string> AskBard(string prompt)
{
var request = new HttpRequestMessage
{
Method = HttpMethod.Post,
RequestUri = new Uri(endpoint),
Content = new StringContent(prompt,Encoding.UTF8, "application/json")
};
var client = new HttpClient();
client.DefaultRequestHeaders.Authorization = new AuthenticationHeaderValue("Bearer", apikey);
using (var response = await client.SendAsync(request))
{
if (response.IsSuccessStatusCode)
{
var result = await response.Content.ReadAsStringAsync();
return result; // 追加:成功した場合には結果を返す
}
else
{
throw new Exception("Request failed with status code "+ response.StatusCode);
}
}
}
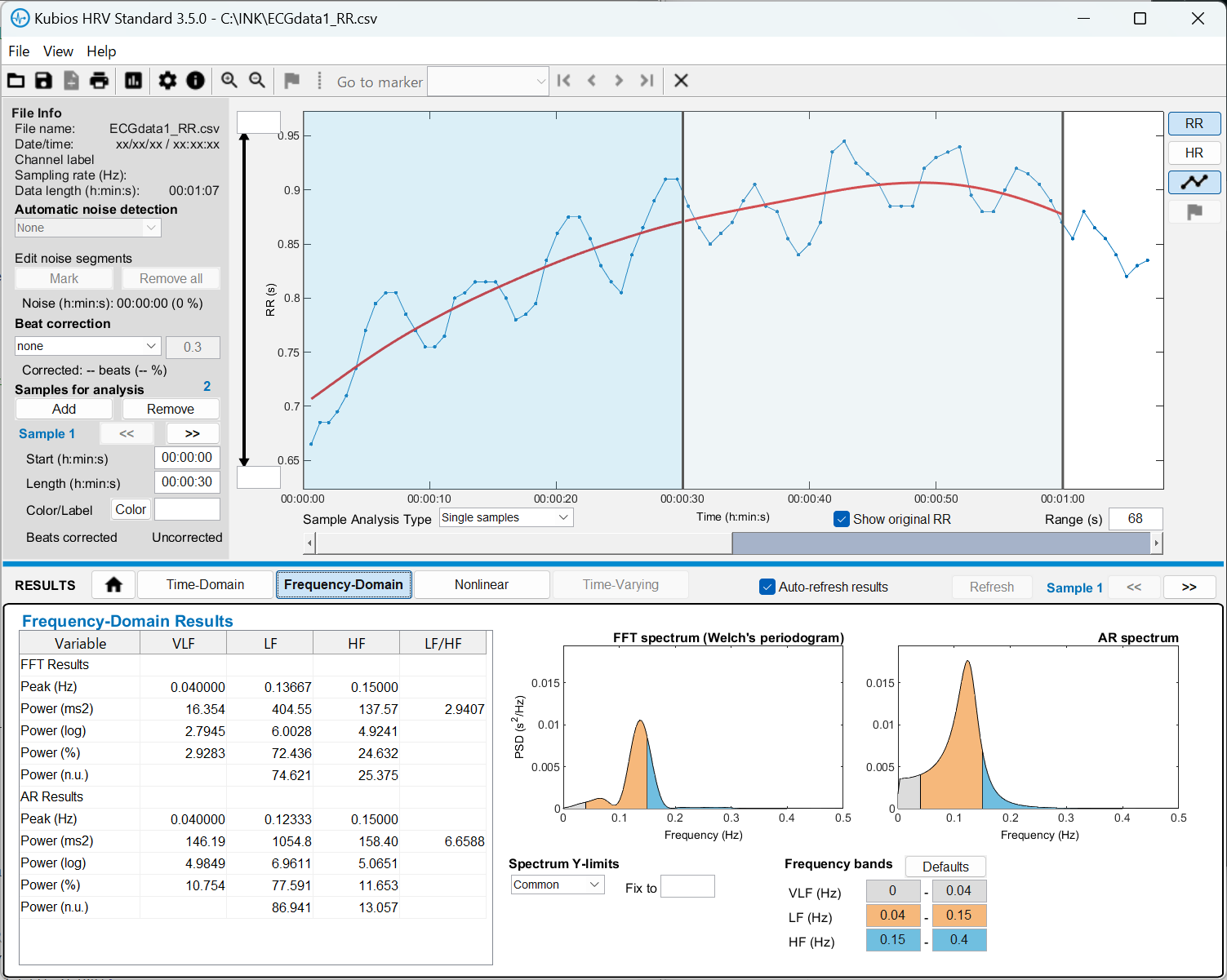
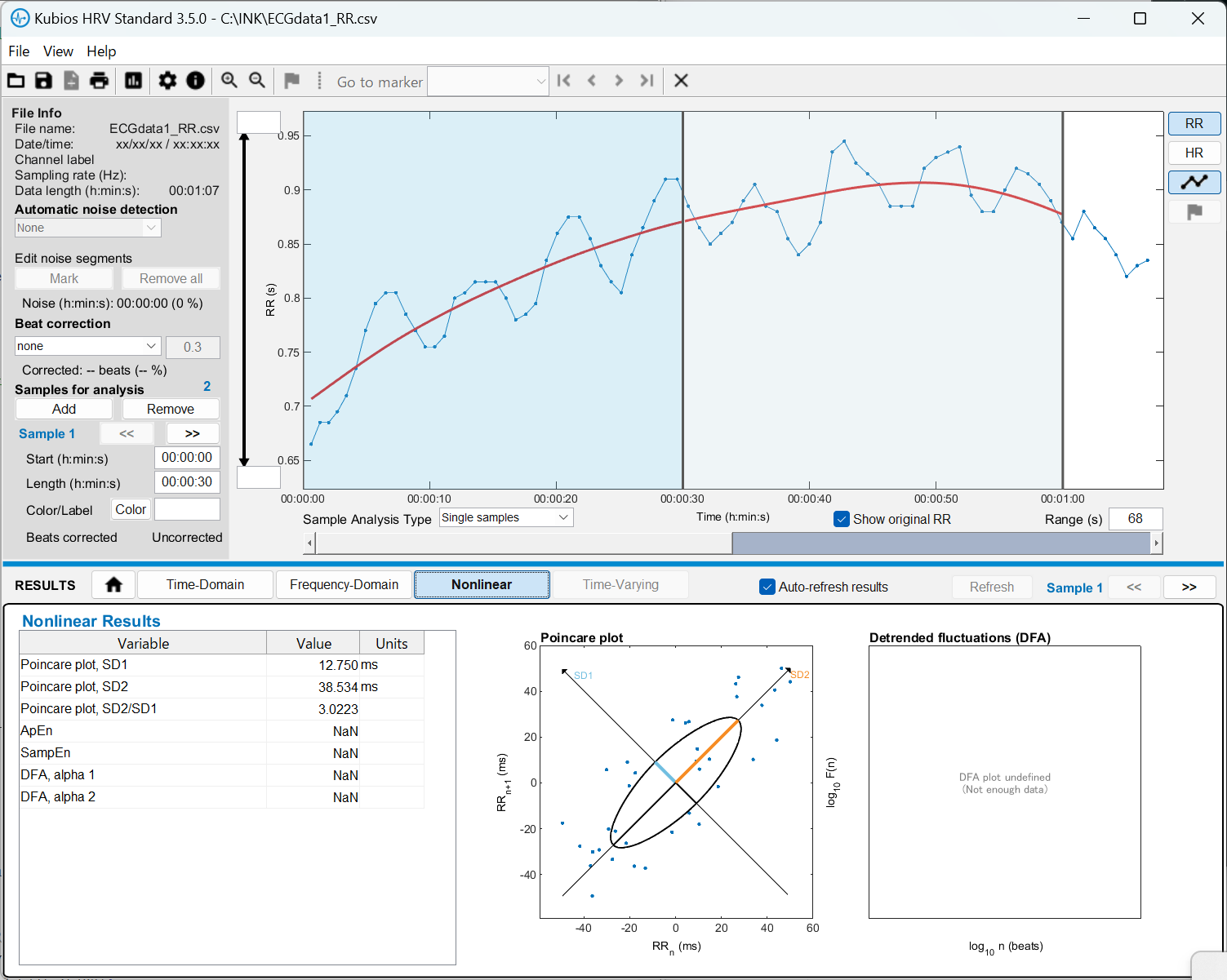
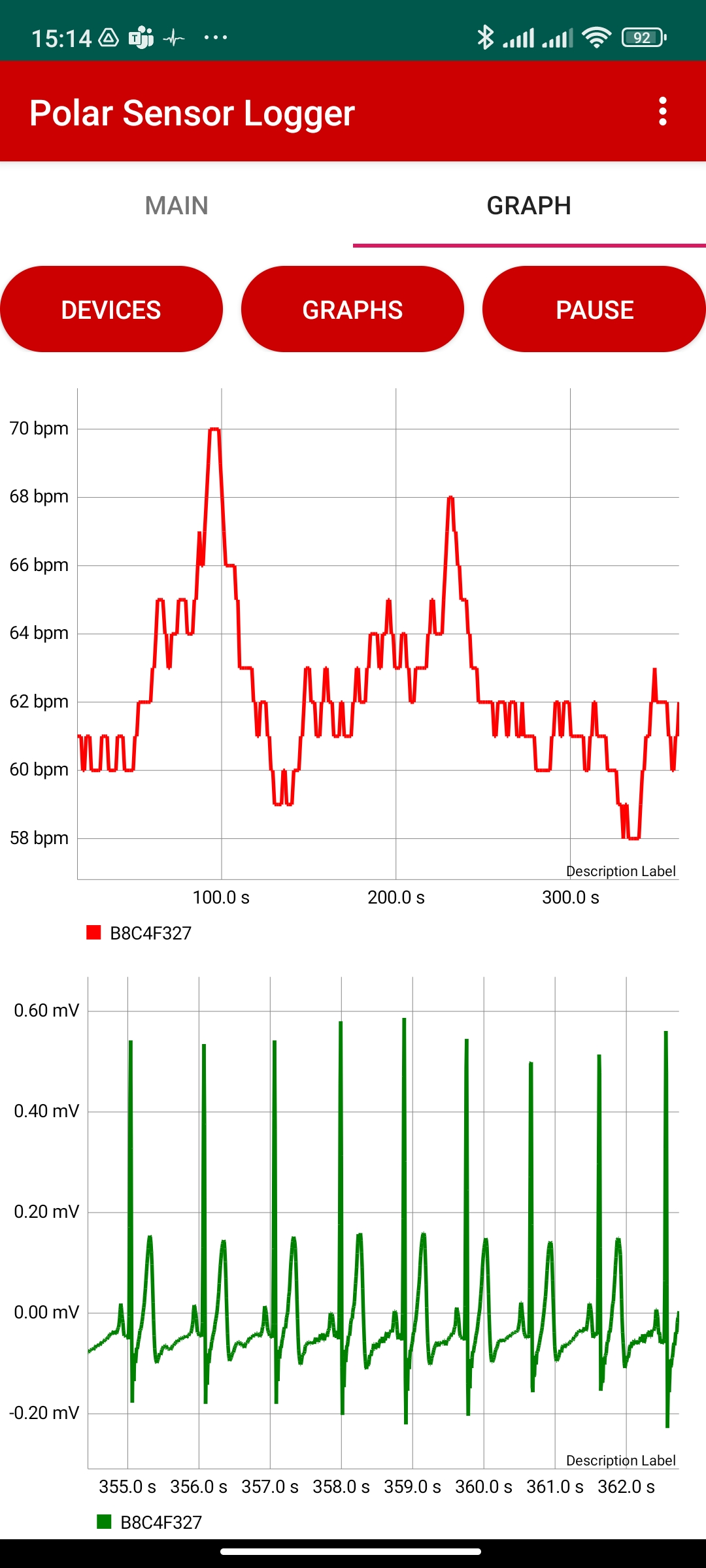
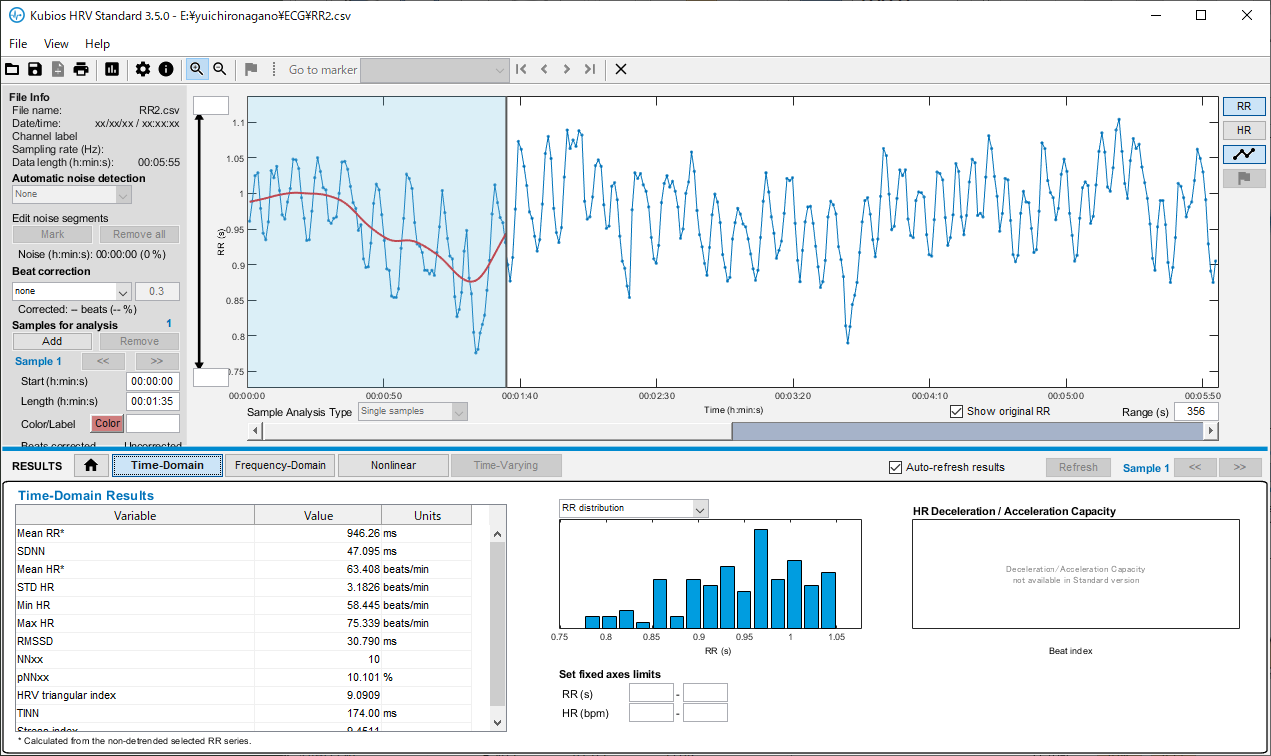
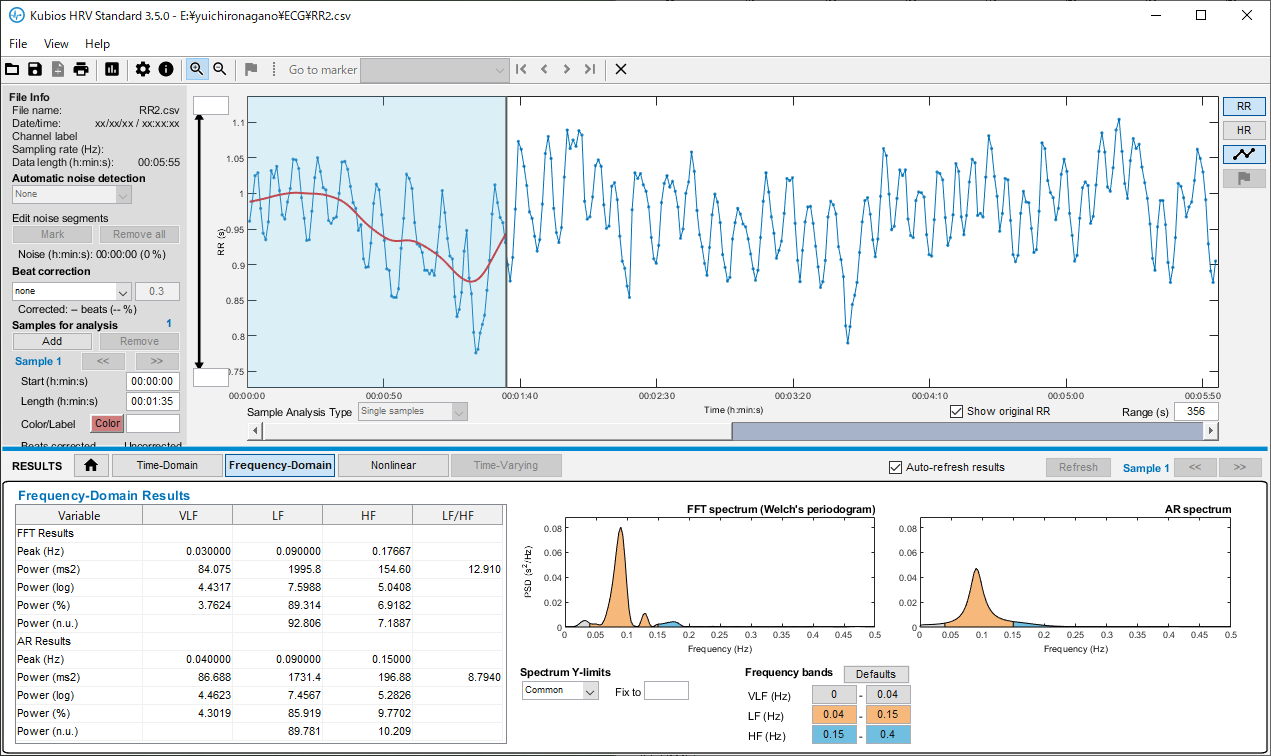
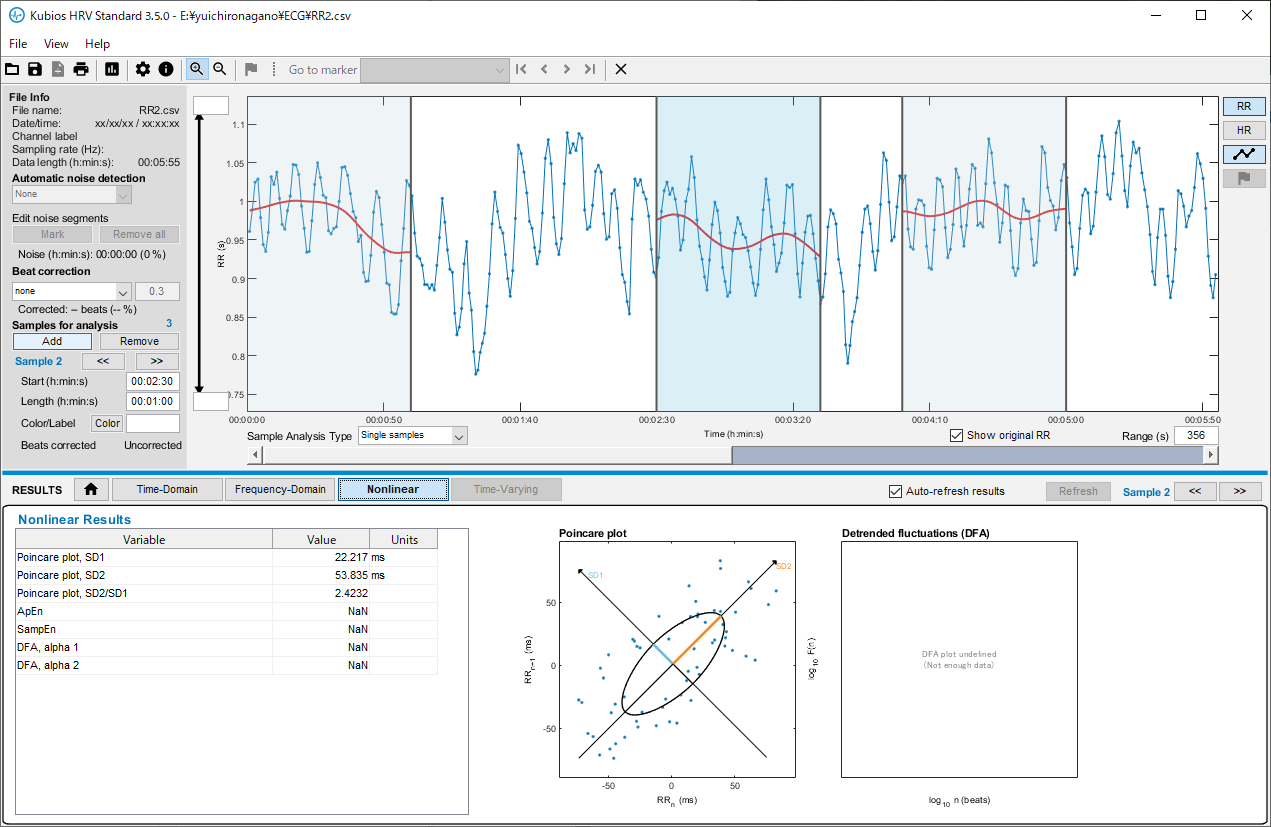
Kubiosへのデータ取り込みとHRV解析 Standard版のKubiosはRR間隔データしか読み込まない。しょうがないので、PolarSensorLoggerが出力する***RR.txtを加工してRR部分だけを食わせてみる。ふむふむグラフが表示されますね。分析区間は、samples for analysisのAddボタンを押して、追加することができる。時間領域や周波数領域だけでなく、非線形のポアンカレプロットなどもできて良い感じです。大抵の分析なら、これで良いのでは。この「いかにも分析してる」感が意外に楽しいのかもしれん。